漫漫疫情何时休?
数据是门视觉艺术 | Links: Covid-19 Dashboard
Summary
疫情爆发至今,我和家人已闭关半年之久。每日最大的忧虑就是,这波来势汹汹的新冠疫情还要持续多久? 于是,我计划用数据探索一下这个问题。本项目要点如下:
- 获取John Hopkins大学实时统计的全球病例数据集
- 使用Parametric Curve Fitting的方式建立统计模型,预测30天走势
- 使用Plotly Dash绘制互动图表,并使用Dash + Dash Bootstrap Components在线部署APP
本项目部署地址
数据来源
数据取自目前最流行的CSSE COVID-19 dataset。该数据集由John Hopkins大学收集各个国家汇总的每日病例数据,在GitHub上开源发布。 数据集地址
建立模型
目前关于COVID-19的模型数不胜数,本项目采用的Parametric Curve Fitting是针对时序型问题简便易行的一种统计学习方法。 这种方法的基本假设是大量的时序数据符合某种概率分布,把误差理解为服从特定分布(通常是高斯分布)的随机波动。 Parametric Curve Fitting的目标是在特定概率分布下,寻找最优化的参数组合,来是的误差最小化。
首先,在这个项目中,我们面对的是一个时序性问题,唯一的自变量是时间。因此,我们需要建立一个关于时间的模型。其数学表达为: \(y = f(time) + error\).
第二,我们需要研究的模型有两个,一个是病例总数的走势,一个是每日新增病例的走势。以意大利为例,让我们来了解一下这两个数据的大致分布。
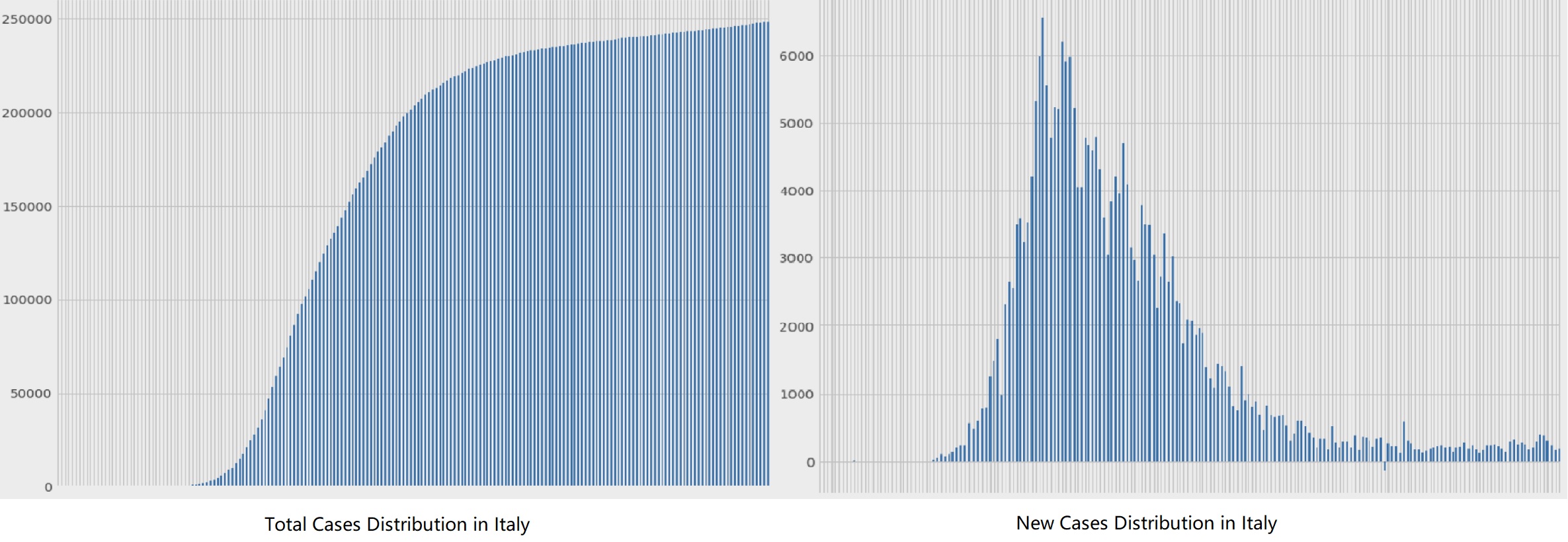
如果我们尝试以各种概率分布的曲线来拟合当前的数据,结果如下:
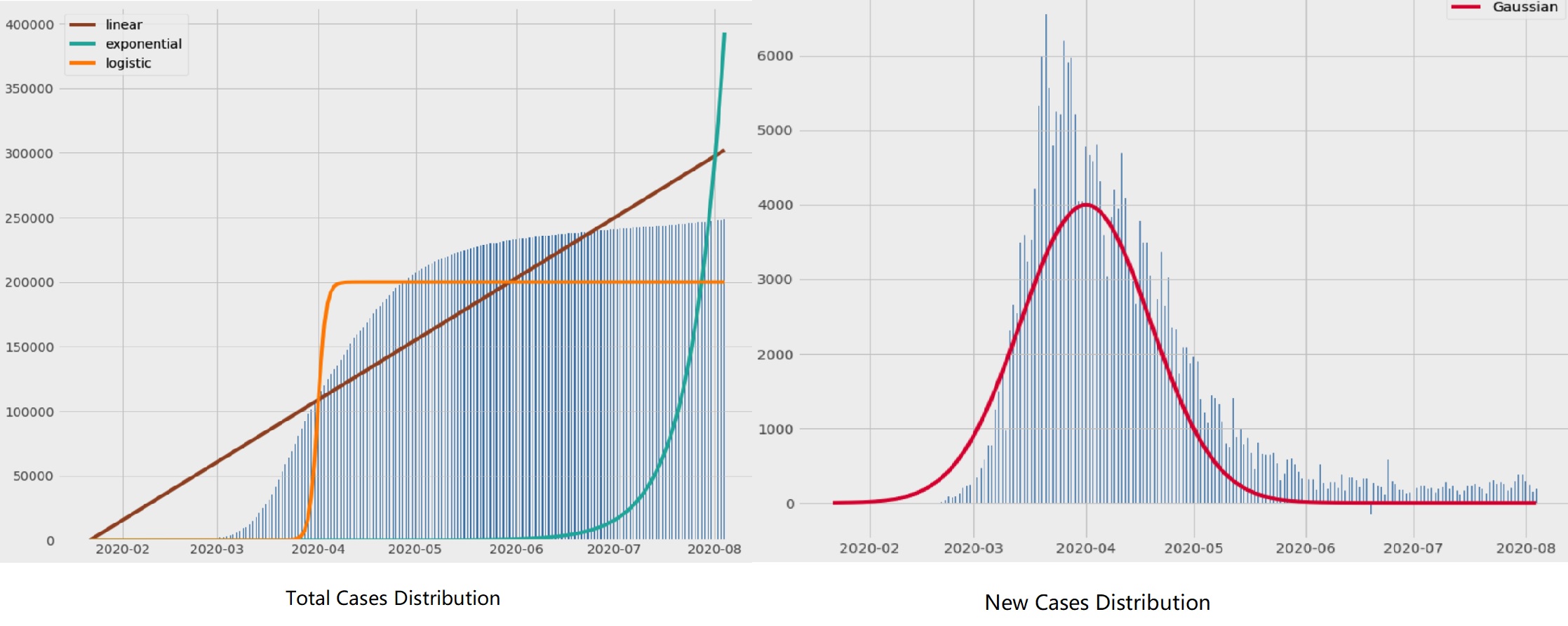
由此,我们得出初步判断:病例总数趋势的发展接近Logistic分布,新增病例趋势更加接近高斯分布。
最后,我们调用scipy optimize库中的curve_fit功能,针对两个模型来学习最佳参数组合。
可视化
基于以上两个模型,我们可以对自”今日”起的30天数据进行预测。
在结果的呈现方面,我使用了plotly Dash对数据绘制仪表盘。用户可以使用下拉列表选择或直接输入想要预测的国家,当前统计数据(蓝色散点或柱状)和模型预测数据(红色填充部分)将会在图表上绘制出来。
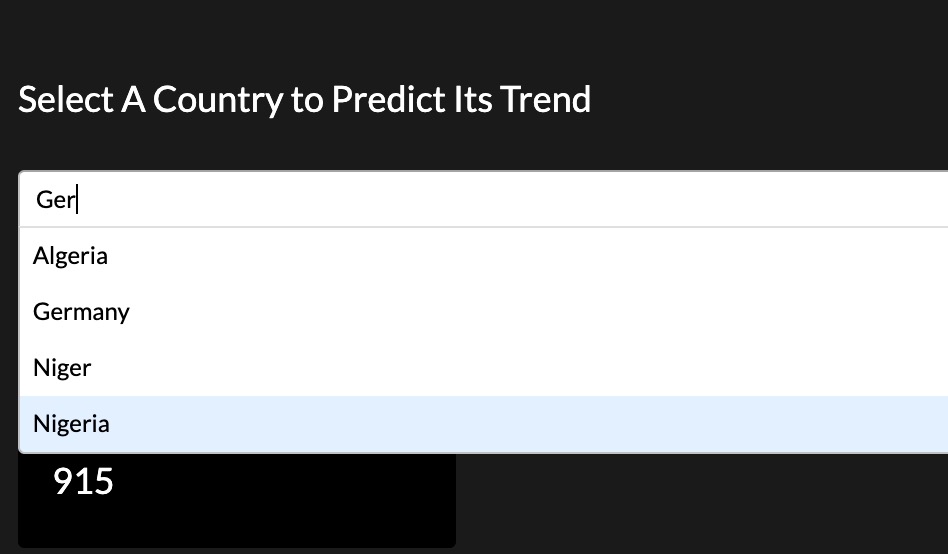

模型部署
最后的最后,我选择在heroku上部署模型。
Plotly Dash本身产出的成果就是一个基于Flask内核的web application,这使得它的Dashboard先天具有产品化的优势。 同时,在这个项目中我引入了Dash Bootstrap Components,使得前端设计效率更高。
Lessons I learned
- 时序性问题有其明显的特点,有时需要考虑机器学习以外的算法模型
- 学习如何设计及实现Parametric Curve Fitting
- 学习使用Dash + Boostrap完成前端的设计和部署
- COVID-19是一个世界难解的问题,目前这个统计学习模型难以泛化更复杂的情形,还有广阔的探讨空间。