下一个赚钱的电影项目在哪里?
精选项目展示 | Links: 访问电影利润率预测网站

I. Summary
电影并不总是一桩赚钱的买卖。对于电影投资人来说,最大的希冀是历练出一双慧眼——一眼看透一个尚未成型的电影是赚钱还是赔钱?可能带来多大的收益?可能的风险是否承担地起? 这个项目就是为此而生。
当然,我们深知电影作品是一种集体性的内容创作,也是一种社会化产品。它的成功与否被很多后天因素,甚至复杂多变的偶然因素所制约。这些都是难以预测和量化的。在这个项目里, 我们考察的是电影的一些基本特征。他们方便量化,并且有规律可循,形成了一个电影项目最初始的DNA。我们着力于对这些特征进行挖掘,构建机器学习模型,进而对电影项目的利润率 进行预测。
然而,仅仅给出一个具有不确定性的预测值,对商业决策的意义毕竟有限。我们认为不如将这种不确定性描绘出来。因此,这个项目的最终预测结果,展示的是指定电影项目的预测利润率,及其在置信水平为90%的置信区间。从这个结果中,我们可以获知最有可能的预测利润率,best case, worst case,甚至标准误差(不确定性的程度)。我们希望这样的预测工具能够给电影投资人提供基本的参考,方便他们根据自己的风险承受偏好进行商业决策。另外,可以观察现有的电影项目有什么突出优势,又被什么所累,为优化项目资源配置提供依据。
本项目要点如下:
- 利用和爬取IMDB,TMDB及The Numbers电影数据集
- 训练关于电影的利润率的单个LightGBM回归预测模型
- 叠加500个LightGBM模型(对样本和特征重新采样增加随机扰动)来模拟预测结果的差异和不确定性
- 最终呈现预测利润率与90%置信水平上的置信区间
- 使用Plotly Dash绘制互动图表,并使用Dash + Dash Bootstrap Components在线部署APP
欢迎使用本项目的在线预测网站: Will The Movie Make Money? [页面首次加载需要30秒,请耐心等待]
APP使用截屏
First things first, 让我们用以上截屏中的信息为例,来看看这个项目到底有什么用?
首先,我们输入了《华尔街之狼》的基本信息,包括片名,2013年12月上映,片长180分钟,预算100 million美元,导演主演人选,类型设定和电影系列信息。当然你也可以输入一部全新的电影或完全虚拟的影片信息用于预测。
点击提交之后,右侧的直方图显示我们叠加500个机器学习模型之后预测的利润率结果,下方的图表提供了更多信息便于理解我们的模型。
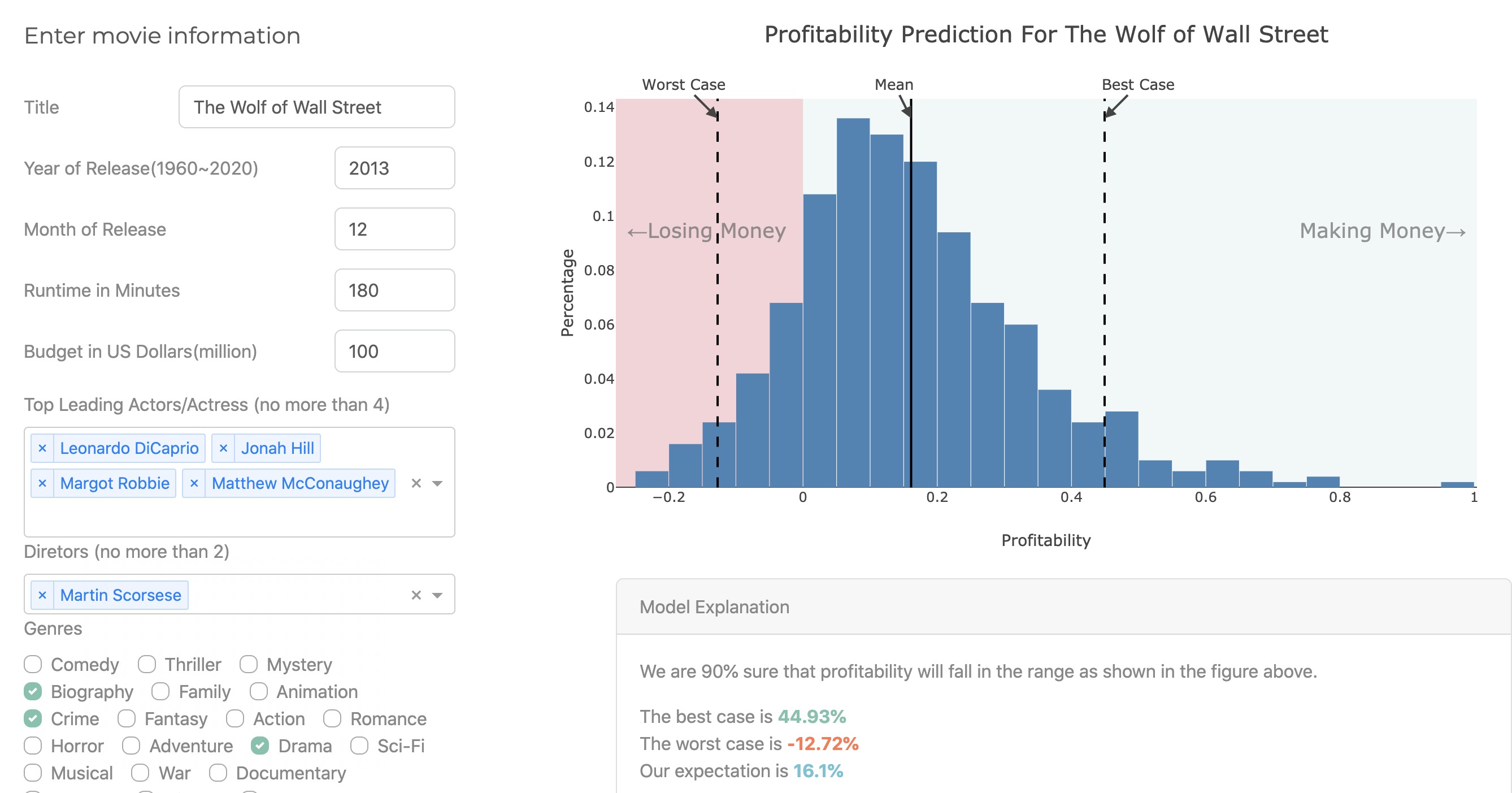
让我们来解读一下这些结果到底在说什么?
- 基于现有的数据和模型,针对《华尔街之狼》这部电影进行预测,我们相信100次预测中有90次,最具可能的预测利润率会落在图中所示的区间(worst case, best case)之中。
- 这个区间中,最好的情形是盈利44%,最差的情形是亏损12%。最有可能的利润率是在16%左右。
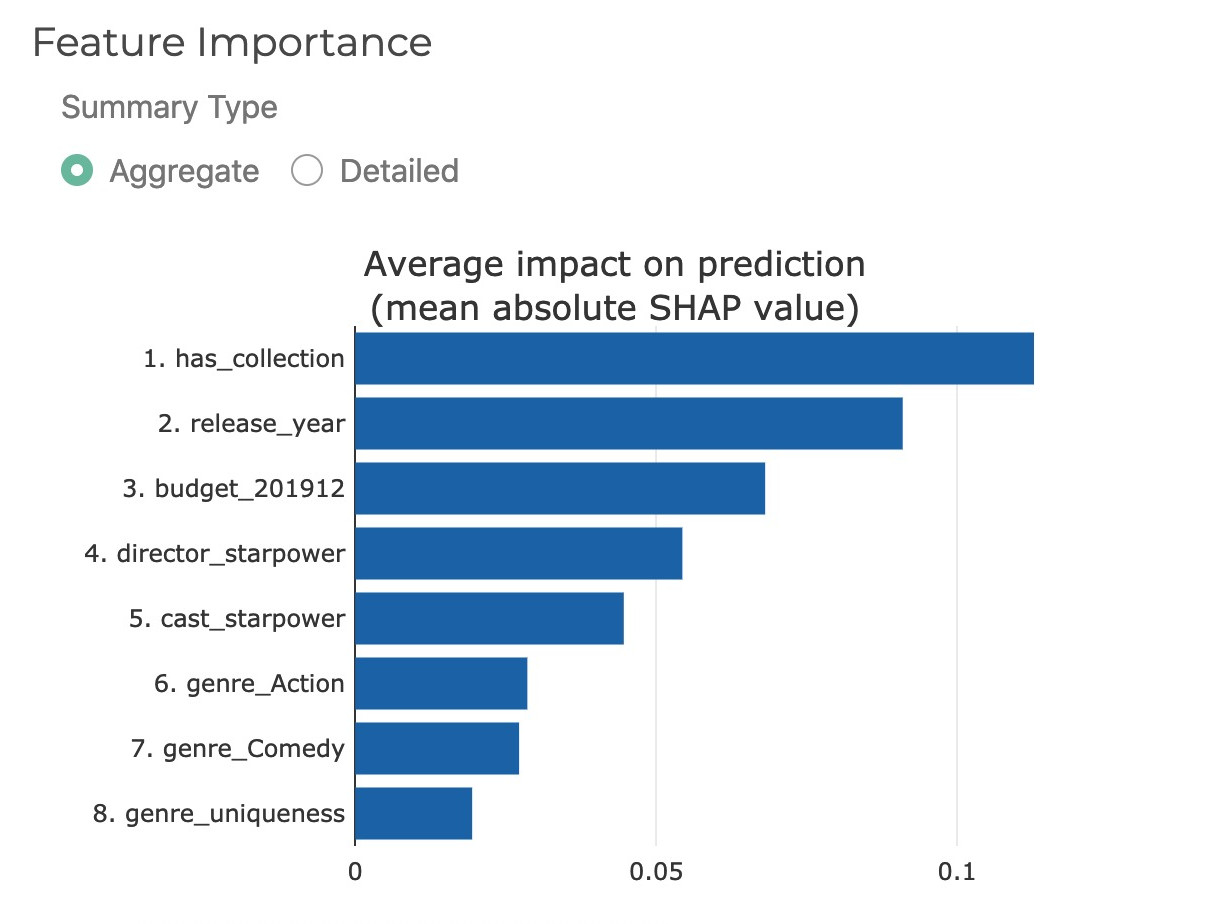
- 在左下的图表中,我们呈现了各个特征对于模型的影响力权重及排序。可以看出,比较重要的几个特征分别是:是否从属系列,上映年份,调整后的预算,导演影响力,演员影响力等。这个排序印证了业内的一个共识:最稳妥的电影投资是拍续集。 另外,一个有趣的发现是:对于美国电影市场来说,导演对于利润率的影响大于演员。
- 具体看这些特征:是否从属系列电影与利润率正相关;上映年份与结果关系比较复杂,但比较新的电影往往会拉低利润率;主演/导演与利润率基本呈正相关的关系。
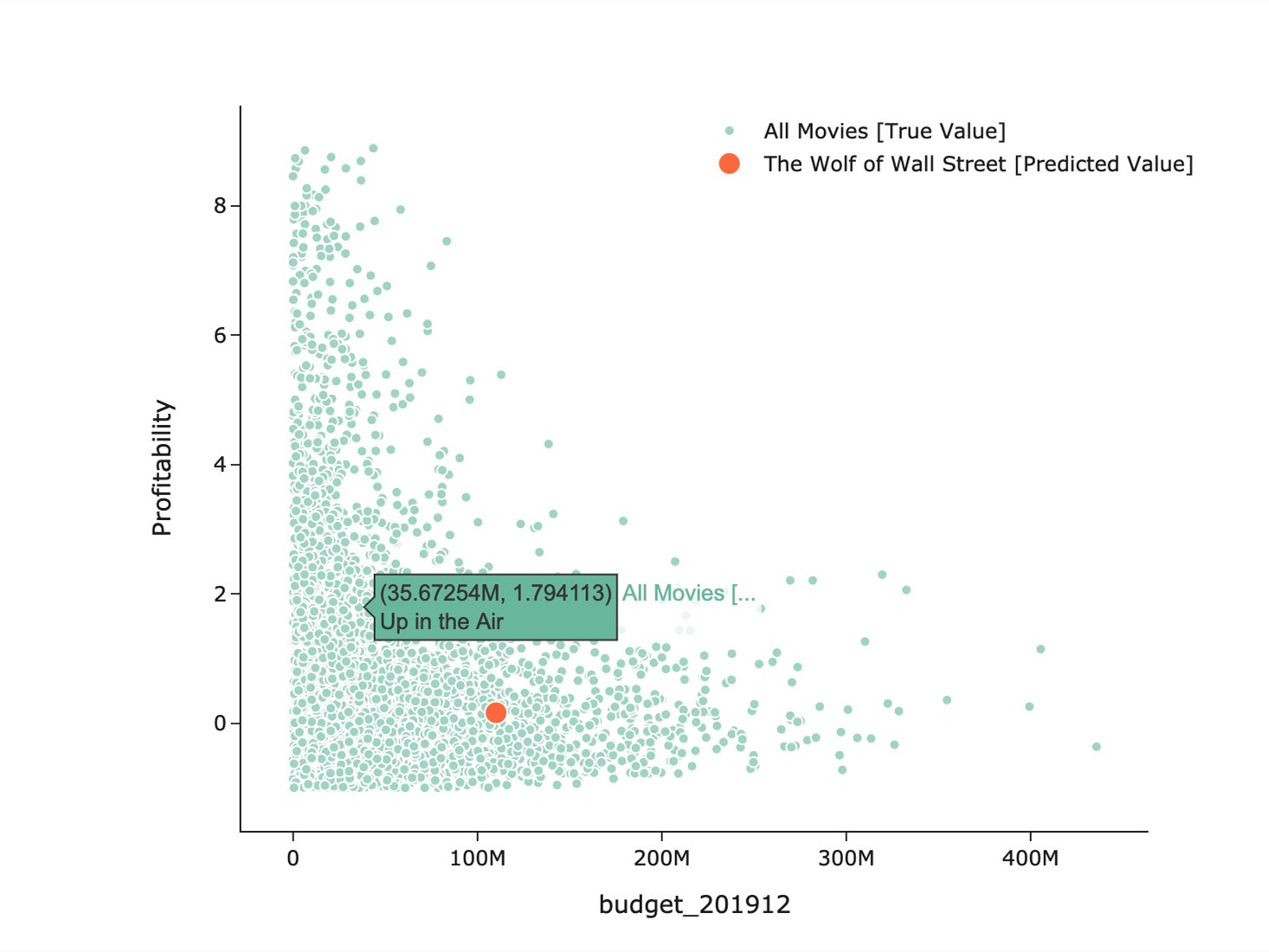
- 放在近5000部电影的数据集中来,《华尔街之狼》这部电影属于预算投资中等偏上,但预测利润率并不算理想的案例。但也符合样本的一个总体趋势,投资越高的电影,盈利能力越保守,但抵抗风险的能力也比较强(利润率的均值和方差都比较低)。 同时,我们发现这部电影的导演影响力,主演影响力都比较高,但过高的预算拉低了整体利润率。
总而言之,如果你是一个偏向保守的投资人,那么这是一个非常适合你的投资方案,因为这是一部大概率会赚钱的电影,但盈利能力比较有限。如果你是一个偏向激进的投资人,那么这个电影项目并不十分适合你,你在等待一个高风险高收益的项目到来。
让我们看看预测结果的准确性怎么样?《华尔街之狼》当年在美国的票房收益是116.949183 millon,利润率是16.95%。看起来很不错,跟我们预测的均值非常接近。
最后,不妨随便更改一下输入,不同的电影配置会带来利润率的变化,说不定有惊喜!
在接下来的篇幅中,我将详细展开介绍这个项目的细节。
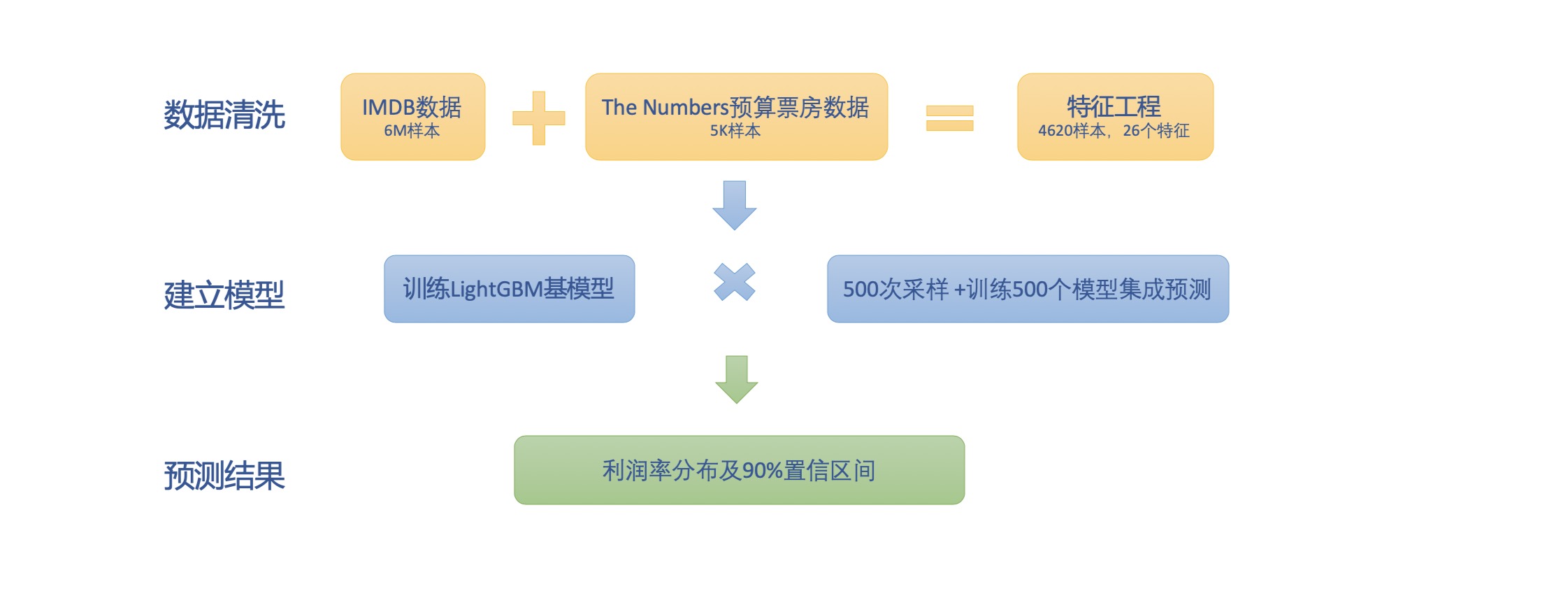
II. 数据来源
本项目的数据取自多个数据源。
IMDB公开数据集:IMDB公开了694万电影的基本信息以及1000万主创人员的作品信息。本项目采用的影片信息包括:片名,IMDB ID,上映时间,片长, 导演,演员,评分,投票数等数据。同时,我们利用主创人员的作品数据,建立了针对378万名演员和80万名导演的影响力指数模型。
The Numbers电影预算和票房数据:美国的电影行业工业化程度高,信息相对透明。即便如此,获取电影项目的 预算信息依然很困难。电影制片厂通常会对电影的真实预算秘而不宣,并且会利用各种财务技巧对向外公开的预算数据进行掩饰,有时故意夸大,有时特意压缩。在这个项目中, 我们爬取了美国电影 行业网站The Numbers公布的5000余部电影的预算和票房数据。或许个别数字跟真实情况依然有出入,但这已经是我们目前能够公开获得的,相对可以信赖的数据来源。
TMDB Kaggle数据集:关于电影项目来说,一个重要的特征是该项目是否从属于一个电影系列。电影续集立足了已有的受众基础,有着 某种先天的商业潜力,电影行业的术语称之为”大IP”。TMDB在Kaggle公布的5000部电影数据中包含这一特征。我们将这批数据跟我们现有的电影数据集结合起来,并且手工订正了一些缺失和冲突的信息。
III. 数据清洗与特征工程
首先,IMDB数据集中的电影有690万之多,我们对研究对象的边界做以下限定:
-
1960年之后上映的电影
-
收益仅考虑美国国内电影票房
第二, 由于数据取自多个数据源,这个项目花费了大量时间用于数据清洗。最大的问题是电影片名在多个数据中的措辞有出入,例如,在IMDB记录中的影片Star Wars: Episode IV — A New Hope,在其它的数据集中 为Star Wars 4: A New Hope。在我们需要依据片名对数据集进行merge的时候,这就是成为了很大的难题。虽然我们可以使用正则表达解决一部分的匹配问题,但仍然需要大量的人工甄别工作。在此不一一细表。
第三,在特征工程中,我们构建了以下几个主要的特征:
- 演员影响力指数 Cast Star Power,计算方式如下
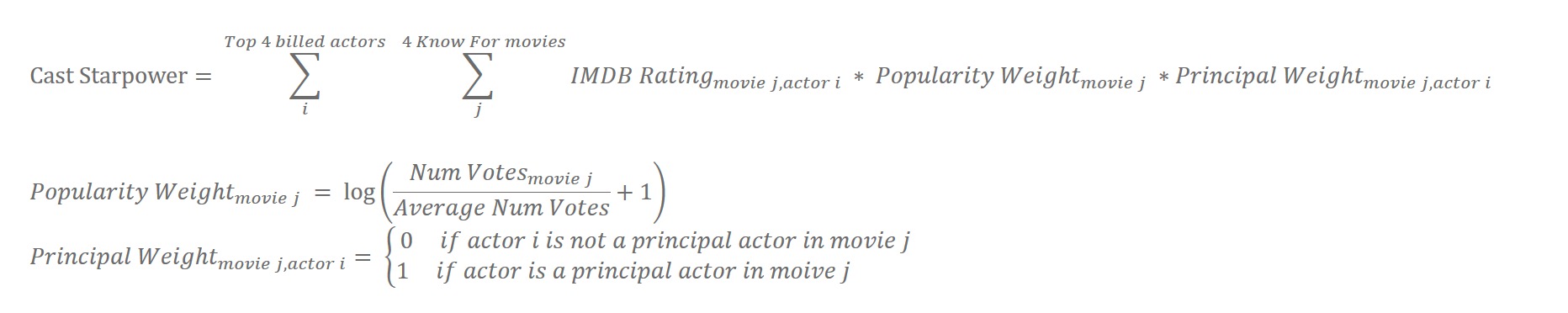
- 导演影响力指数 Director Star Power,计算方式类似演员影响力指数

- 类型独特性 Genre Uniqueness,计算方式如下

-
预算/票房购买力转换 使用美国劳工部的CPI指数,将电影上映当年的预算和票房数据转换为2019年12月相应的购买力,使得 各个年份的消费数据置于统一的度量之下,可以直接比较。例如,1947年1月10万美元相当于2019年12月的120.3166万美元。
-
其它类型 数据集中一部电影可以从属于多个类型,而有些类型中样本量非常有限,对模型的贡献也比较小,包括:Musical,War,Documentary,Western,History,News,Sport。 我们将这些类型统一归类为Others。
- 对演员影响力,导演影响力,调整后的影片预算离散化 基于一定的标准对三个连续变量进行离散化,为模型增加非线性特征。具体的分类标准如下:

- 转换预测目标为:log(Profitability +1) 这个项目中,我们的实际预测目标是利润率。
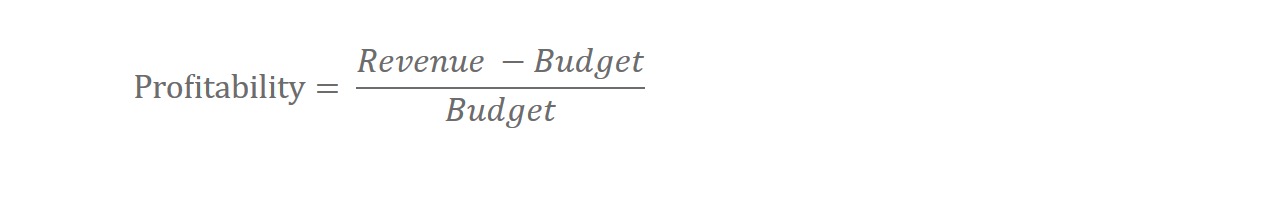
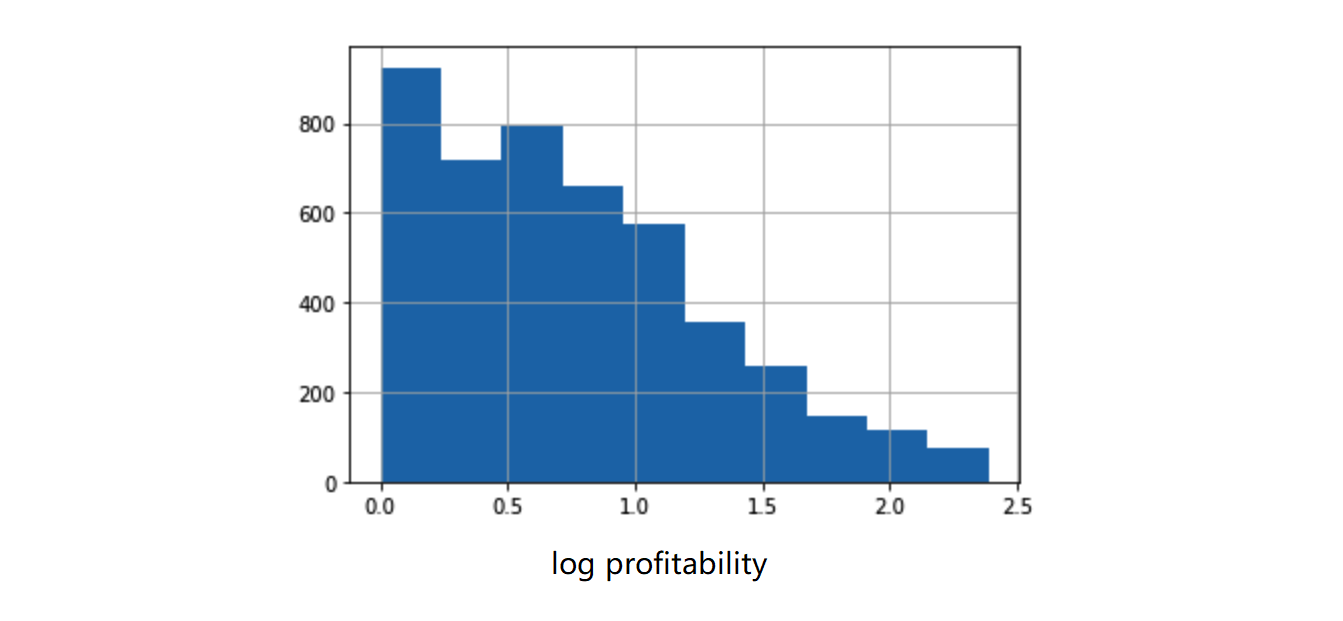
但实际情况是很大比例的影片利润率集中在-1到0区间。因此我们将模型中的预测目标转为log(profitability + 1),削弱负值堆积对模型的影响,使得target分布略显均匀一些。 当前目标分布如下。
IV. Data Exploration
我们通过对现有数据集的数据分析,有以下发现:
-
预算与演员影响力、导演影响力有强烈正相关性
-
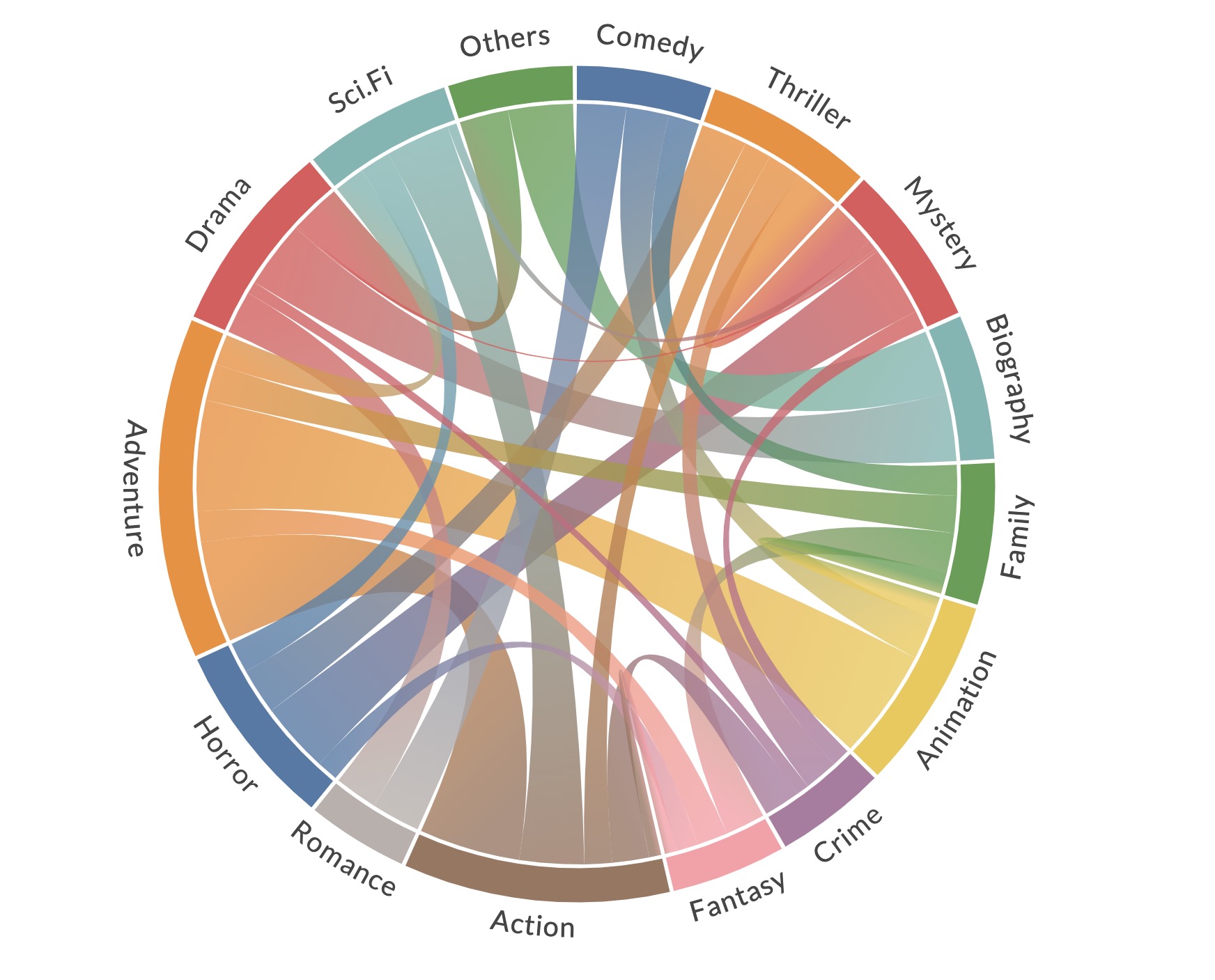
动作类型,动画类型与预算有强烈正相关性
下图显示了类型之间的相关性[仅显示正相关性]:相连弧线的粗细代表了两种类型同时出现的频率。例如,冒险与动画同时几率最高,冒险与动作也经常同时出现
Co-occurrence of Movie Genres: interactive plot
影响力指数最高的20位演员

影响力指数最高的20位导演

V. 建立基模型
最终送入模型进行预测的特征共26个:
-
上映年份
-
上映月份
-
片长
-
演员影响力指数
-
导演影响力指数
-
调整后的预算(相当于2019年12月消费水平)
-
类型独特性指数
-
类型:对以下特征进行独热编码,包括:Comedy, Thriller, Mystery, Biography, Family, Animation, Crime, Fantasy, Action, Romance, Horror, Adventure, Drama, Sci.Fi, Others
-
是否从属电影系列
-
演员影响力离散化
-
导演影响力离散化
-
预算离散化
我们选择LightGBM作为基模型,原因如下:
-
我们希望使用树的集成模型来应对电影收益预测偏差较大的问题,因此着重考虑XGBoost和LightGBM模型。
-
鉴于LightGBM是优化版的XGBoost,具有速度快,内存占用低的优质,更加有利于模型在线部署,因此成为我们的最终选择。
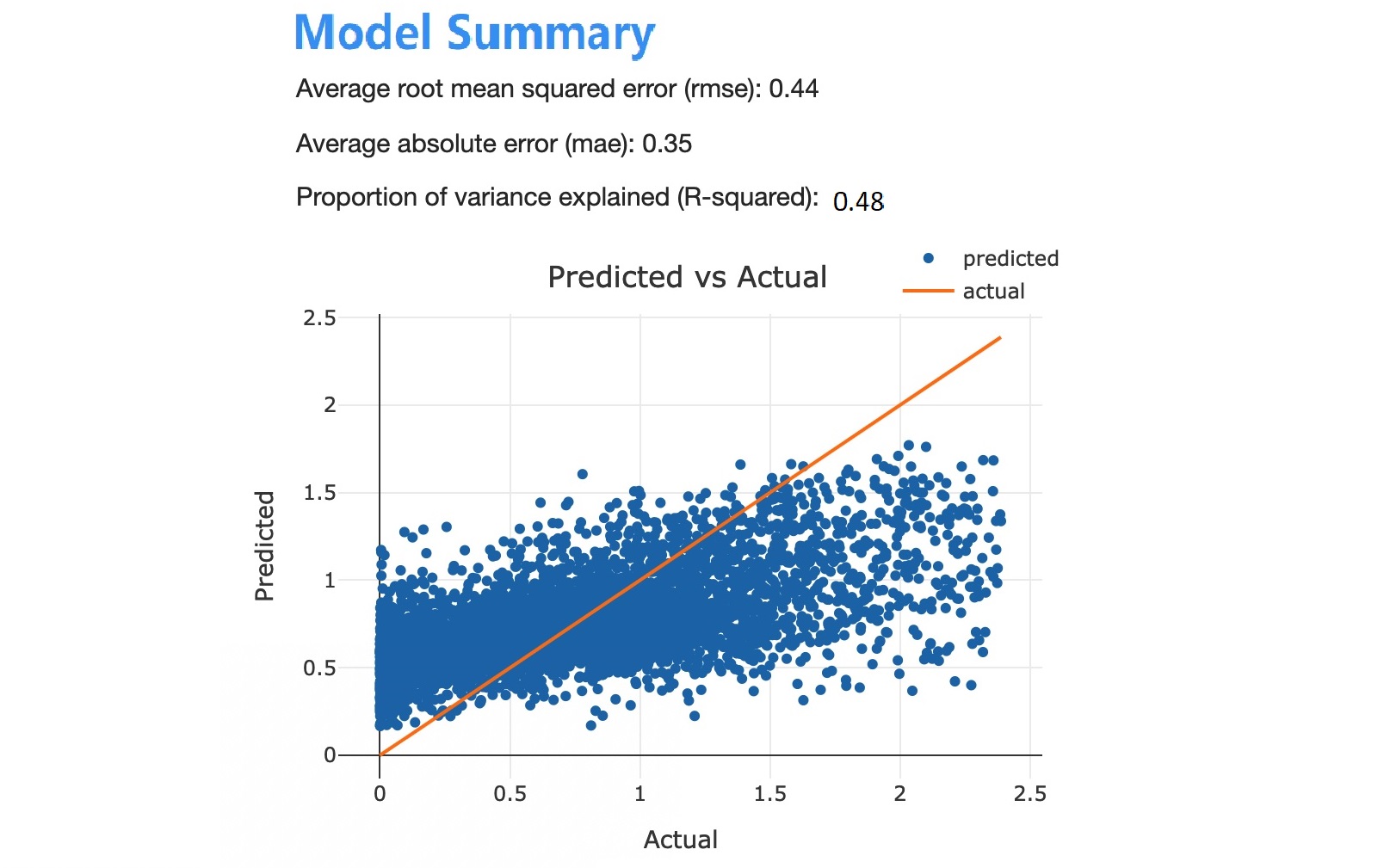
针对这一模型,我们使用randomized search方法对超参数调优,主要调节的超参数包括:num_leaves, max_depth, learning_rate,以及l1/l2正则化系数。 使用RMSE和R2作为评估标准,基模型表现如下
VI. 概率仿真与置信区间
从上图可以看出,预测电影项目的利润率相当困难,不可避免的存在一定的偏差以及相当大的方差。单单以一个这样的预测值来决策电影的生死,有点过于草率。与其这样, 不如将这种不确定性以量化的方式表达出来。我们受Bagging思想以及蒙特卡洛仿真方法的启发,设计了一个具体的操作方案:
- 对训练集样本进行500次随机采样,每个样本的数量为总样本量*0.7
- 使用这500个训练集训练500个具有差异性的LightGBM模型
- 进行500次预测,预测结果生成一个预测利润率分布。
- 在这个分布上,我们计算了90%置信水平的置信区间,呈现给用户最有可能的利润率,worst case和best case。
- 推断总体均值:根据中心极限定理我们知道样本均值总是围绕在总体均值周围呈正态分布,因此我们可以根据样本均值来估计总体均值,即为最可能的预测值。
- 推断标准误差:\(\mathrm{SE}=\frac{s(\text { 样本标准差 })}{\sqrt{500}}\)
- 选择90%置信水平:我们选择较高的置信水平,同时又希望置信区间不要过于宽泛失去参考价值,因此确定为90%.
- 计算置信区间
- 下界为:总体均值 - z-score*标准误差
- 上界为:总体均值 + z-score*标准误差
- 90%置信水平对应的z-score为1.64
由此,整个模型的总体结构如下:
VII. 模型解释
我们建立一个模型,不仅在于用它能预测,更在于通过模型我们能解读出来各种特征的重要程度以及之间如何交互。 SHAP是用于模型解释的一个很好地工具。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。相比常用的特征重要性,很明显可以看出,SHAP的优势在于能反映出每一个样本中的每个特征的影响力,而且还能表现出这种影响是正向影响还是负面影响。
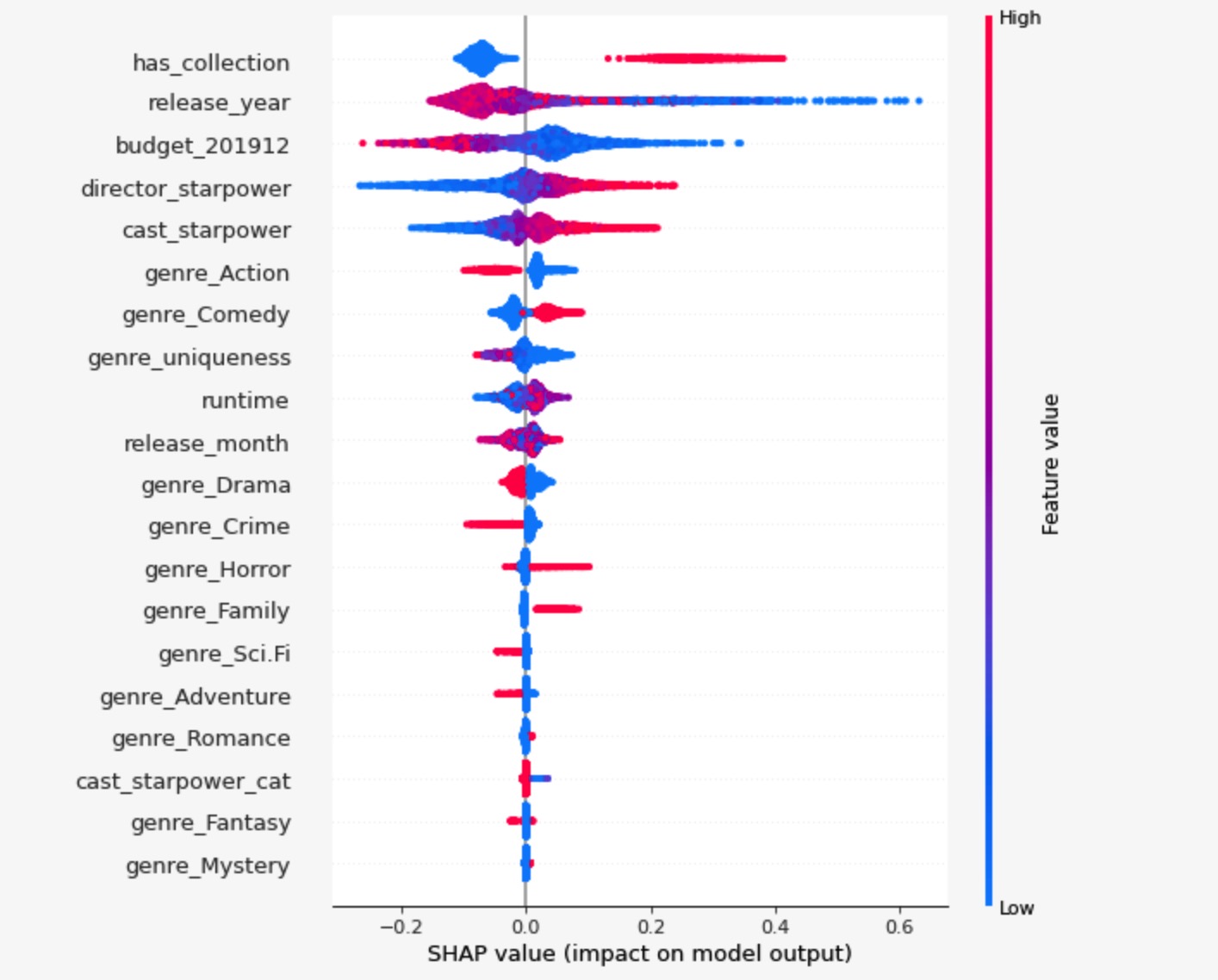
以上Summary Plot呈现的是从SHAP角度呈现的特征重要性。
- 我们可以看出是否从属于电影系列是最重要的特征之一,电影系列对于预测利润率的提升非常明显。
- 而发行年代的增长对利润率起到的作用是负面的。年代越近,利润率越低。
- 影片预算在利润率预测中毫无疑问也很重要,但由于它最终在利润率计算中是以分母形式出现的,因而预算越大越不利于利润率的提升。
- 导演影响力和演员影响力对利润率有正向提升的作用,这一发现并不让我们感到意外。但是有趣的是,导演影响力是排在明星影响力之前的。
- 在各种电影类型中,喜剧片跟盈利更相关,而动作电影更不易盈利。
既然SHAP的优势在于解释每个样本中特征的影响力,我们不妨通过Force Plot来看一下个体样本是如何受特征影响的。
图中展示了200部电影的聚合特征力图,光标划过每一个电影,我们可以看到这部电影的什么特征在推高利润率,什么特征在拉低利润率,以及特征在多大程度上起作用。
最后,我们还可以通过描绘LightGBM中树的分裂方式来看特征中哪些特殊的值成为了重要的分水岭。
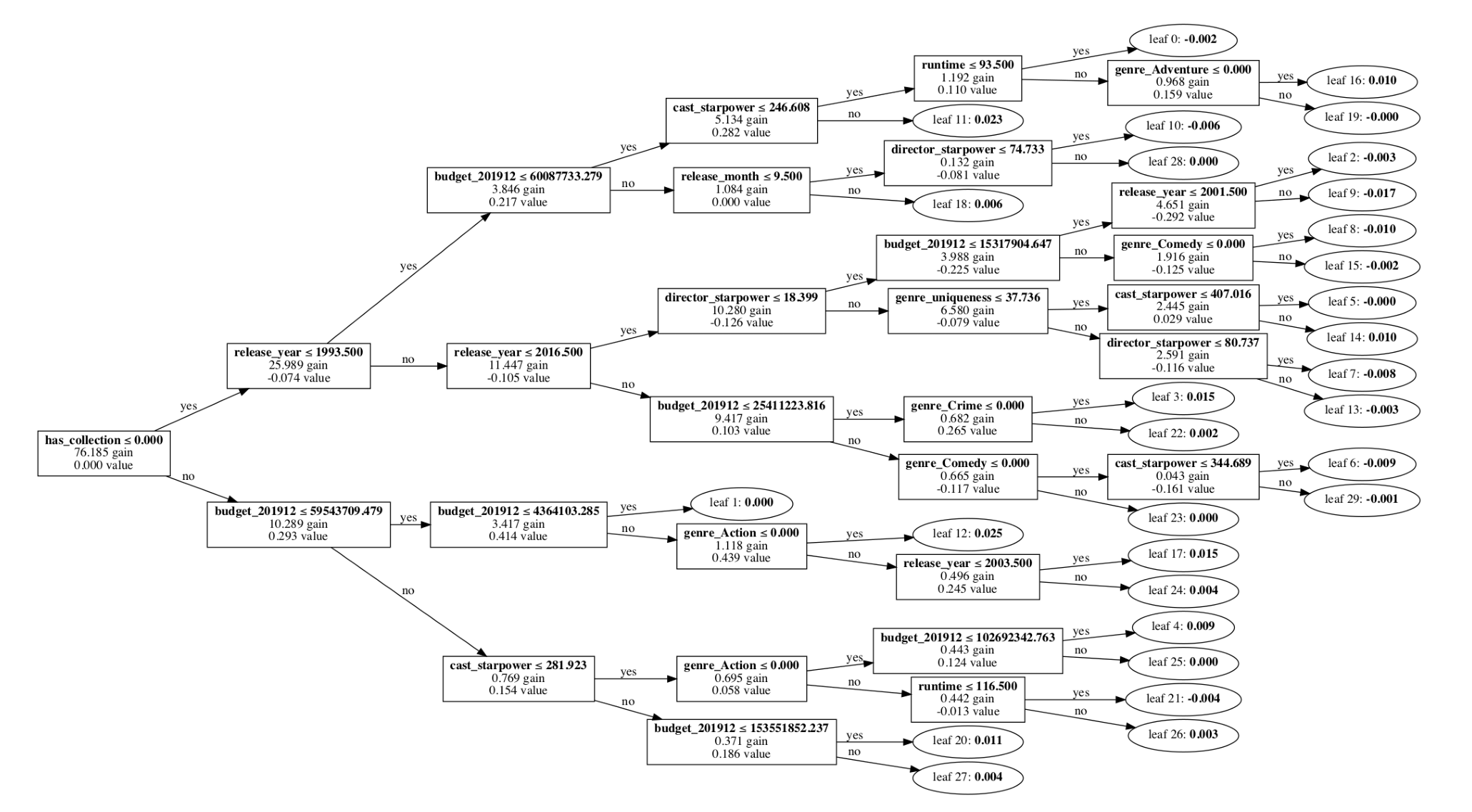
例如,一部预算在436万美金以上5954万美金以下的,系列动作电影,在2013年之前上映是有小幅赚钱的额可能的。 一部1993年之前上映的电影,预算在6000万美金以下,如果明星影响力大于246是有可能赚钱的。但如果明星影响力小于246则不太会赚钱。
VIII. 可视化及模型部署
对一个机器学习最好的检验是将其产品化。因此,我们决定将模型部署在heroku上,并且将预测结果使用plotly Dash绘制互动性Dashboard。
在APP页面上,用户可以在Dashboard左侧的表单输入影片的基本信息。接着,500个模型的预测结果就会出现在右上区域。图表标明了90%置信水平上的置信区间,上界和下界分别为best case和worst case。红色区域为利润率小于0的部分,即亏损;绿色区域为利润率大于0的部分,即盈利。同时,预测结果的离散程度体现了不确定性的程度。
除此之外,为了方便投资者理解预测结果,我们绘制了特征权重图,用于呈现到底哪些特征对预测结果起到了更重要的作用。同时,在右下角的图表中,用户可以方便地查看重要特征与利润率之间的互动关系,以及该预测影片的特征/利润率与样本库中影片相应特征/真实利润率的比较结果。
IX. 进一步优化的空间
- 当前的模型仅纳入了一些便于量化的特征,进一步优化可以考虑使用NLP技术将剧情、关键词等文本特征转化为向量放入模型。
- 演员影响力/ 导演影响力指数有进一步优化的空间,在更有力的数据支持下,可以考虑将主创人员的商业价值纳入计算体系,同时考虑规避data leakage的方法,甚至进一步考虑加入时间衰减因素。
- 影响电影利润率的另一个因素是同档期竞争问题,需要探索更合适的算法衡量这一特征。
X. Lesson I Learned
- Data Science的根本目标是用数据来解决问题。数据科学家必须时刻从业务需求出发来理解和思考问题。对业务的理解决定了机器学习的方向,而具体的模型算法决定的只是数字。
- 这个项目跟Kaggle竞赛或其它算法学习不同,我们面对不是Toy Data,也不是现成的整理好的数据,而是一个real world problem. 我们不仅需要收集整理数据,更要对数据的可信赖程度进行甄别。前期比较大的工作量是对于Full Stack Data Scientist工作的一个挑战。