如何用打折挽留住你的客户?

I. Summary
本项目来自于波士顿咨询公司数据科学团队的虚拟实习项目。 面对英国能源企业PowerCo客户流失问题,通过机器学习挖掘客户流失的主要原因,寻找可行的商业解决方案。数据科学只是纸上谈兵?Welcome to the real world!
本项目要点如下:
- 训练LightGBM分类模型预测客户流失概率
- 通过模型解释客户流失的主要助推因素
- 验证打折策略的可行性,从利益最大化的角度优化打折对象
最终提交的项目报告概要如下:

欢迎查看本项目完整代码
II.项目背景
PowerCo是一家英国能源企业,向商业机构,中小企业以及住宅户提供电力和天然气服务。近些年来,伴随着欧洲能源市场电力自由化的发展,PowerCo出现了比较明显的中小企业客户流失。于是,他们向波士顿咨询的GAMMA团队寻求帮助。
在这个数据科学咨询项目中,客户关心的问题有以下几点:
- 客户流失的主要原因是什么。就客户目前的推测,客户流失可能与价格敏感有关。
- 一个20%的打折策略能否有效地应对当前问题
- 如何以最优化的方式选取打折对象
PowerCo提供的数据包括2015年的客户消费资料,客户历史定价记录以及客户流失信息。
要验证价格敏感是否导致客户流失是主要原因,用数据科学的角度,可以表述为:“跟价格相关的特征是否能在预测客户流失率的过程中起到重要作用”?一个可行的思路是:训练一个分类模型来预测客户流失率,进而查看特征重要性,判断价格相关因素是否起到重要作用。
III.特征工程
通过数据清洗(处理缺失值、处理异常值、处理不匹配数据类型等),可供我们利用的数据有53万多条,20个特征。同时,通过基本的数据可视化,几点初步发现值得一提:
-
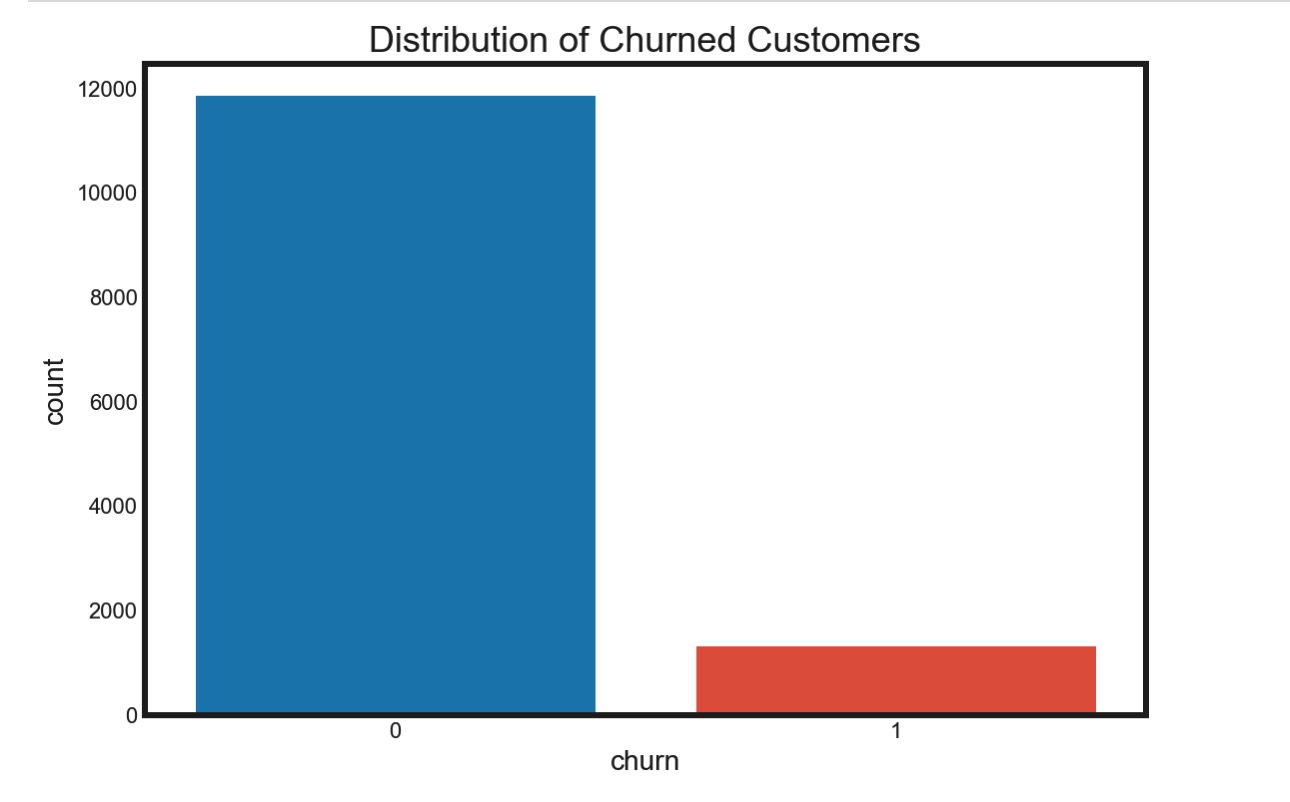
预测目标(客户是否流失)分布不平衡,现有客户中大约存在10%的流失率
-
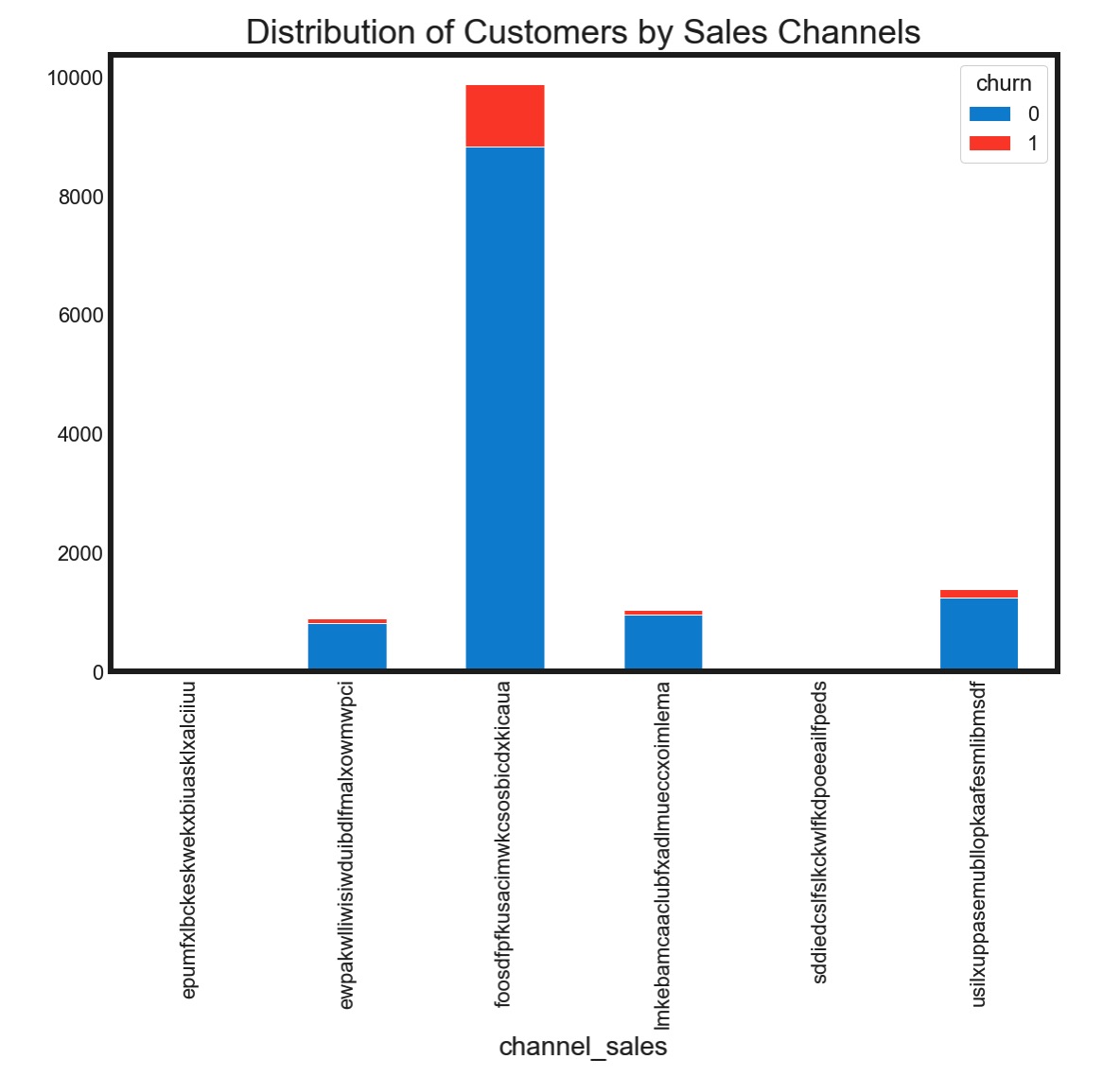
绝大多数客户集中在某一个销售渠道,相应的,该渠道的流失客户绝对数量居高
-
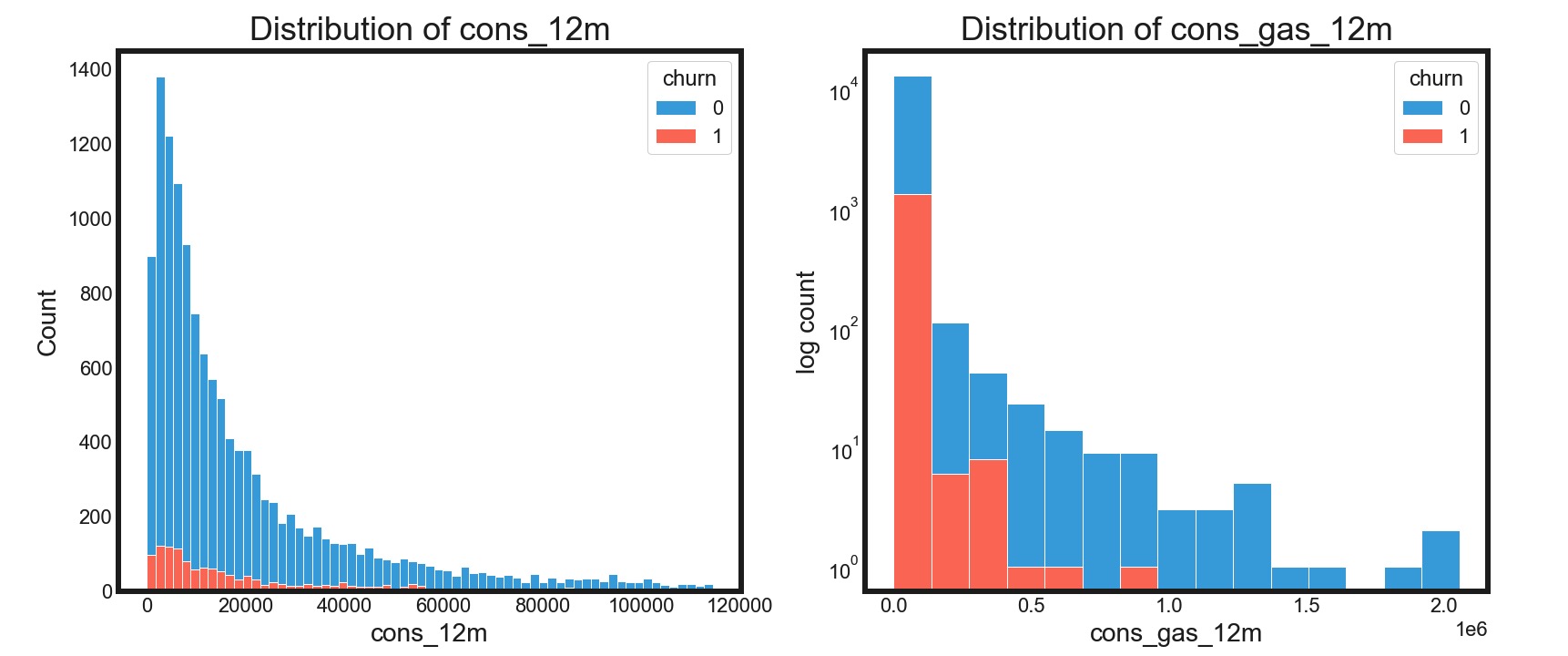
客户的电力和天然气用量数据均呈现极其倾斜的分布,绝大多数的用户集中于用量较小的范围内,少数客户用量极大。呈现明显的长尾分布趋势。
-
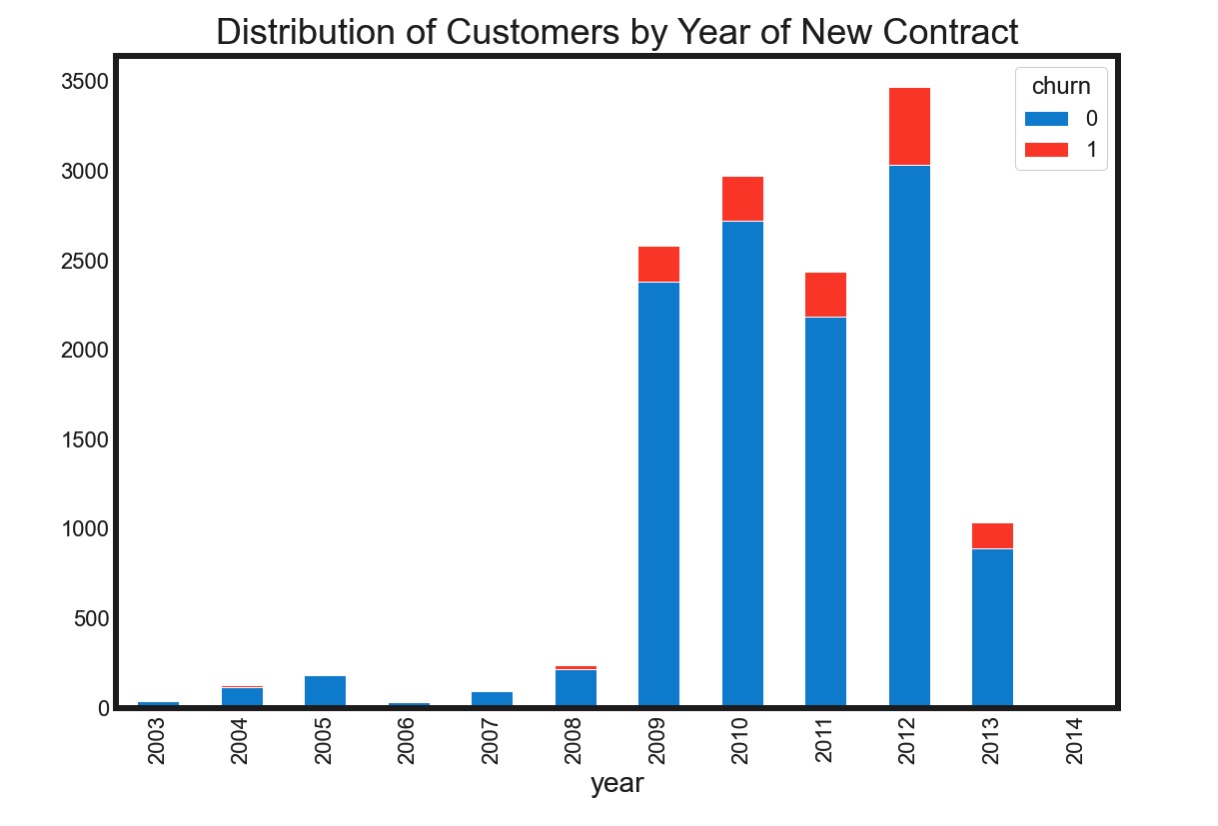
现存用户中,很大比例来自于2009~2013年的新签署的合约。相应的,这几年新加入的客户流失率也比较高,尤其以2012年为甚。
-
流失客户相对集中于特定的价格区间中
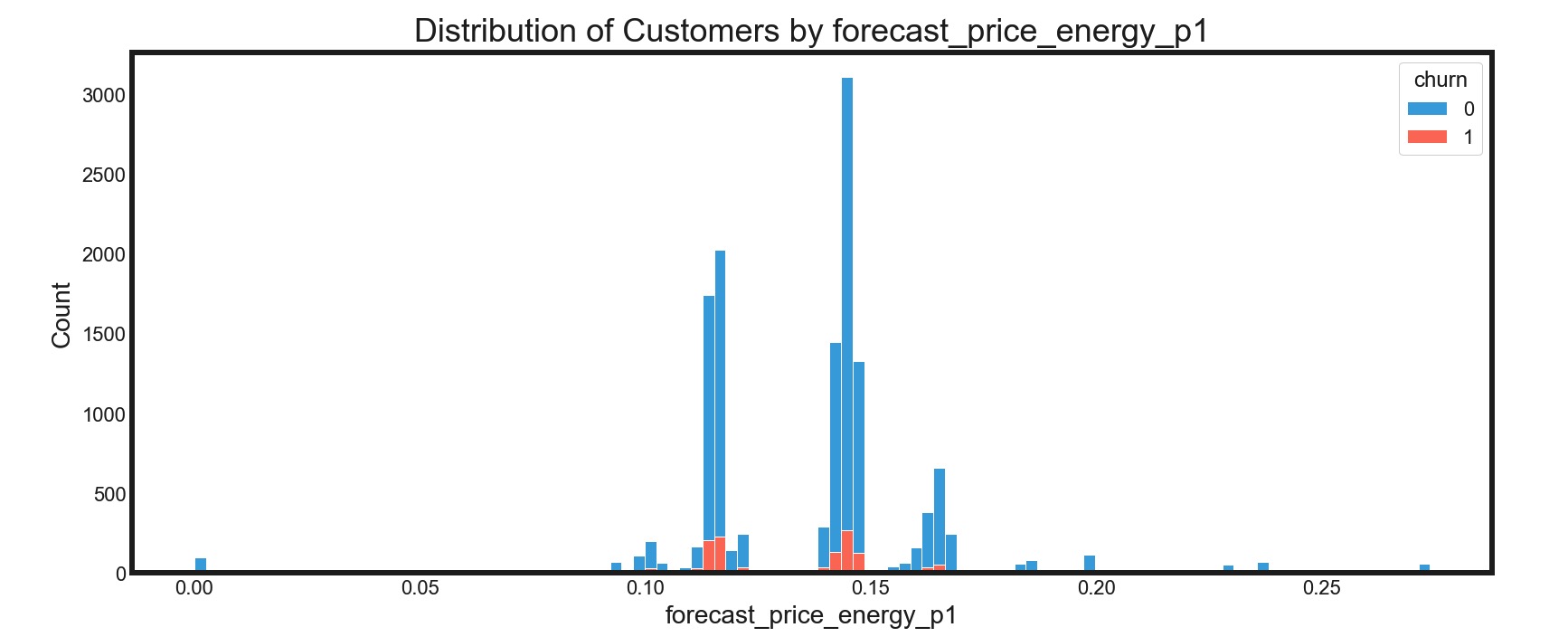
-
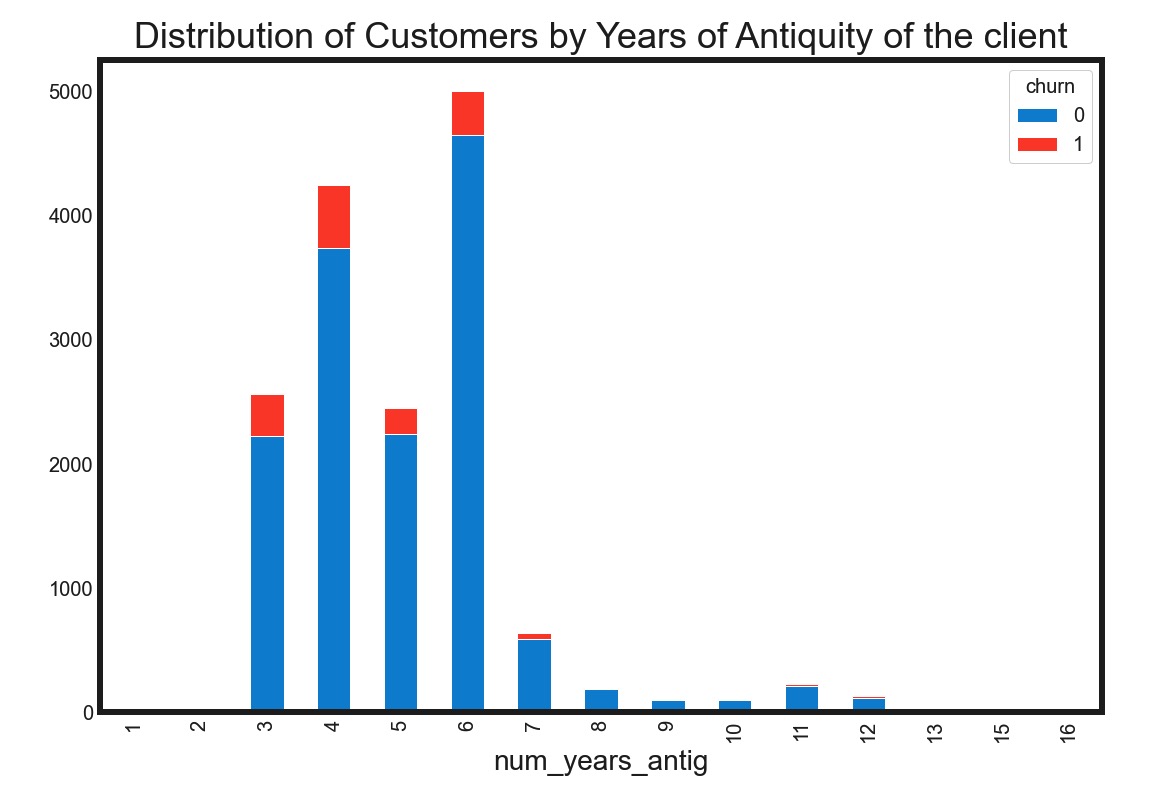
从合同的存续周期来看,3~6年的老客户有比较高的流失率
-
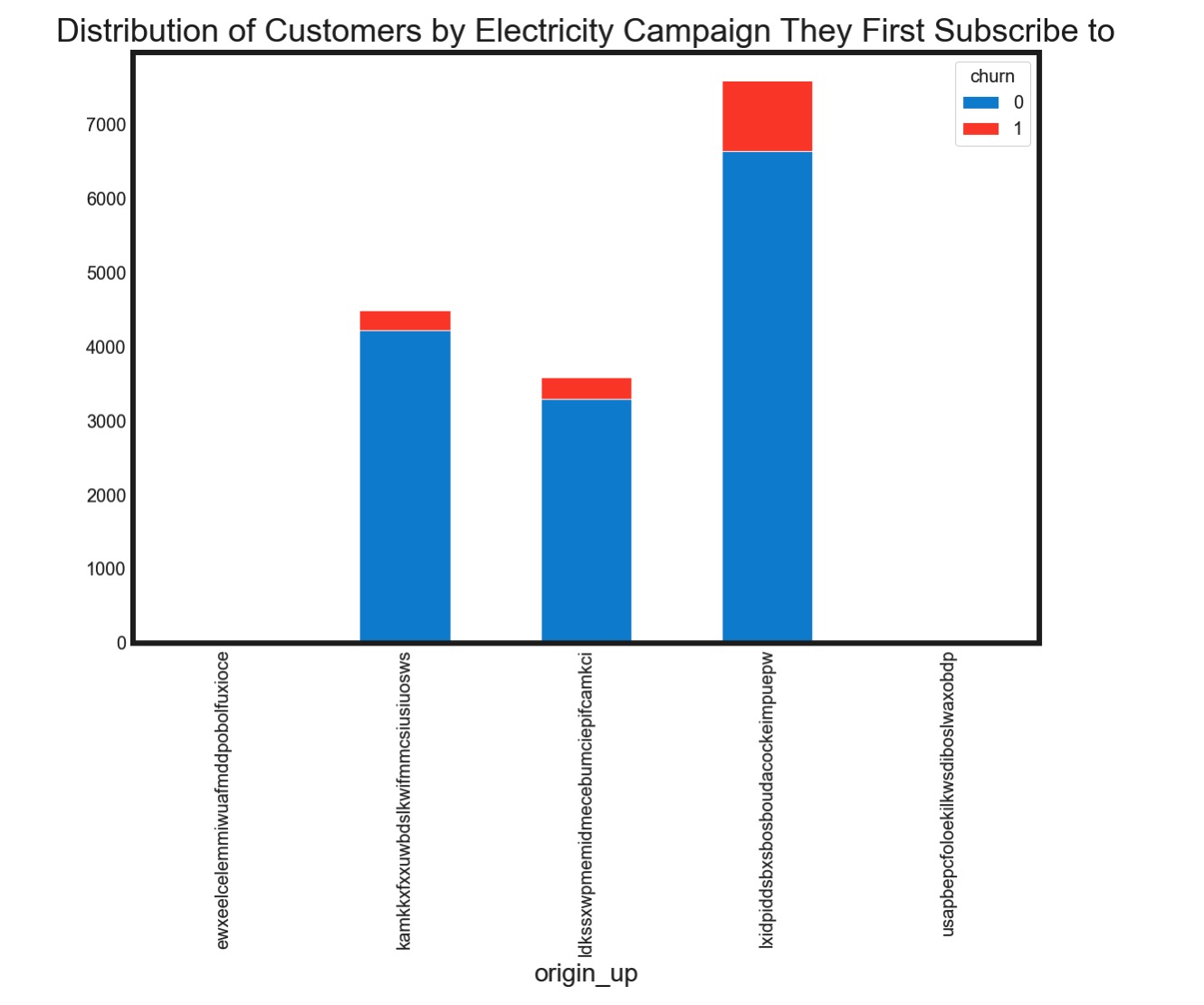
大多数客户是因为特定的促销活动加入进来的,但是需要注意的是,个别促销活动例如’lx’反而会与高流失率有着某种联系
经过处理,最终放入模型的特征总量为52个。主要特征工程如下:
- 对偏态严重的特征进行log转换
- 对类别特征进行label encoding或one-hot encoding
- 时间特征处理
- 提取用户加入的年份
- 提取合约生效、截止、更改、更新到当前参考日(2016-01-01)的时间差
- 批量处理每个用户每个月份消费记录
- 针对每个用户,每种价格等级提取平均值,标准差,近6个月的移动平均,近3个月的移动平均
IV.建模
首先,使用20%的比例,随机划分训练集和测试集。
然后,在默认参数的前提下,建立Logistic Regression, Random Forest, LightGBM三个基模型。由于样本不均衡,本项目采用ROC-AUC作为模型衡量标准。通过基模型的对比,最终选取LightGBM作为主模型进一步进行探索。
选定模型之后,我们使用hyperopt对模型进行finetuning。重点调整的参数包括:
-
提升模型表现的参数:num_leaves, max_depth, learning_rate, num_iterations
-
防止过拟合的参数:min_data_in_leaf,,bagging_fraction, feature_fraction, lambda_l1, lambda_l2, early stopping
使用最佳参数,重新训练LightGBM。得到训练集AUC score为0.69, 测试集AUC score 0.66。我们将训练集和测试集的AUC score保持在0.03以内,以确保模型不会过拟合。同时,测试集预测准确率达到了0.89。
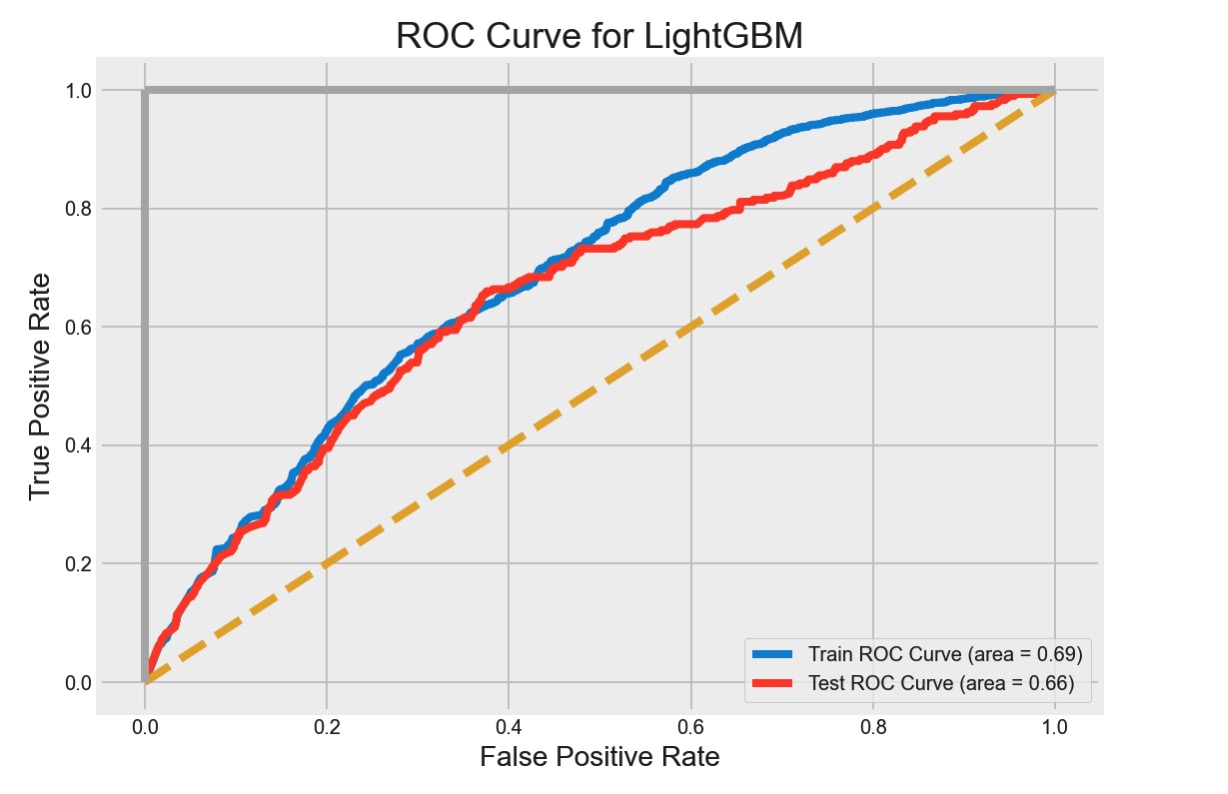
从平衡Ture positive rate和false positive fate的角度,我们可以找到一个对客户的最佳分界点。通过计算,这一分界点在0.308左右。这意味着,预测概率>0.308的用户,我们判断为即将流失的客户,剩下的为可以留存的客户。

V.模型解释
我们使用LightGBM模型自带的方法和SHAP对模型进行解释。
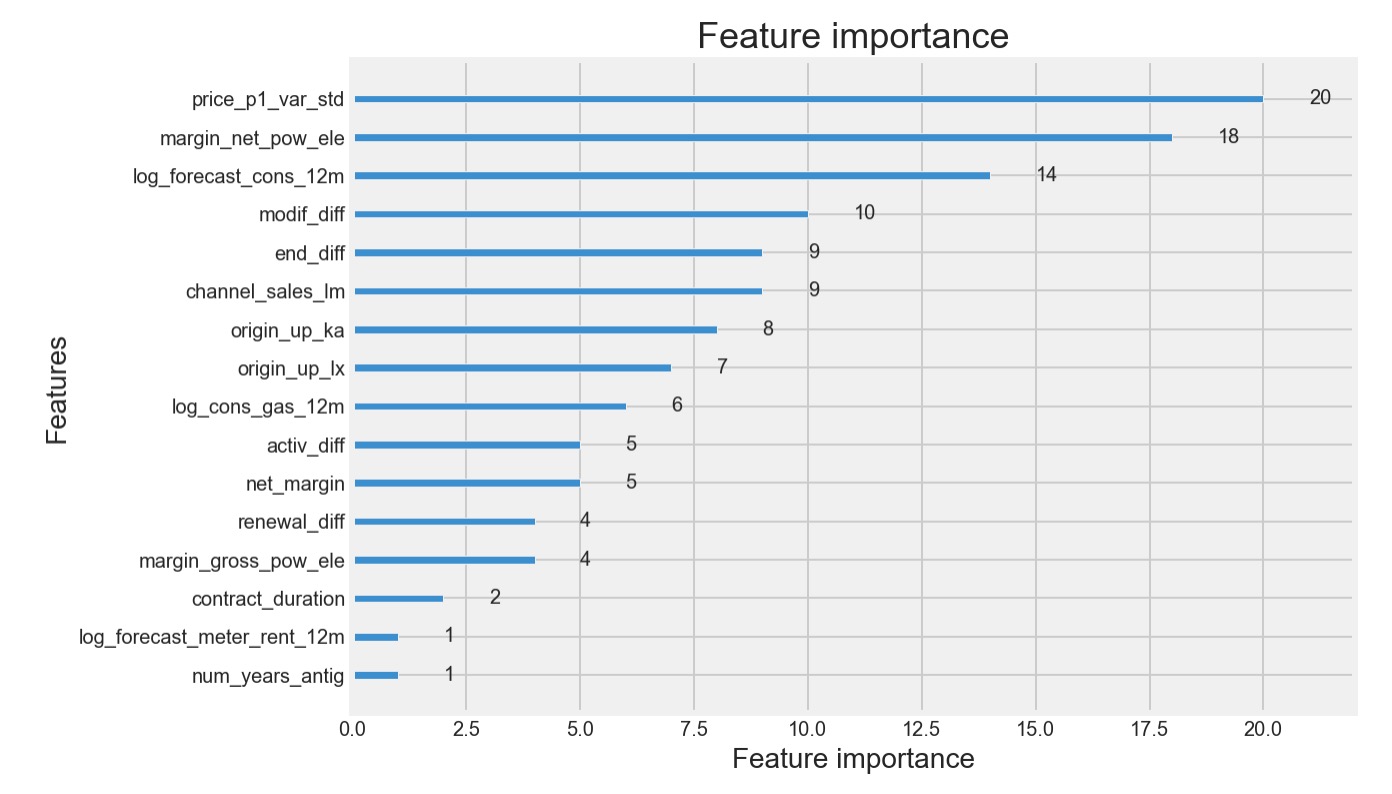
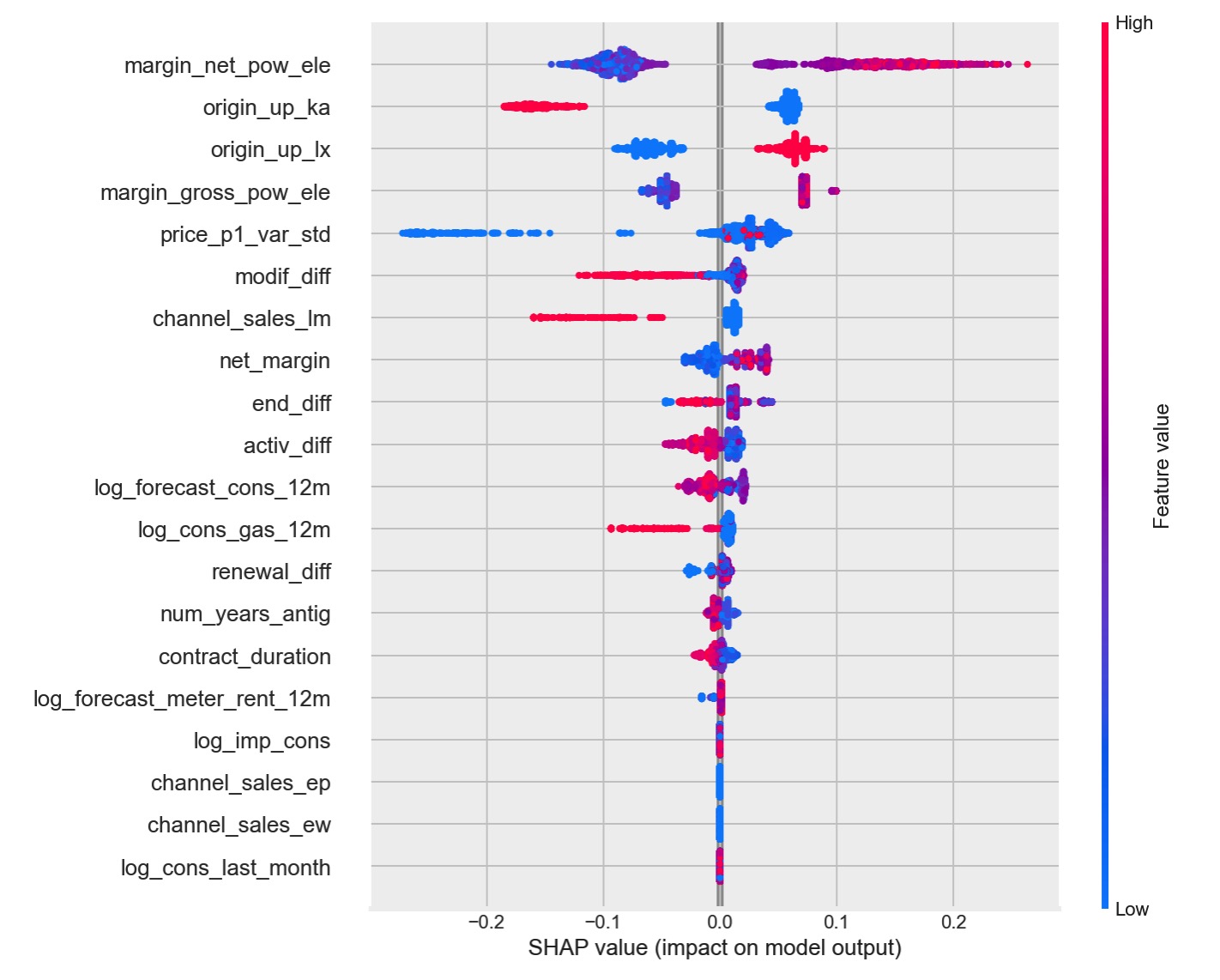
综合两种对模型的解释,我们可以得到以下发现:
-
最为重要的特征之一是net margin on power subscription, 即供电服务获得利润情况。这是一个与价格息息相关的特征。可以明显的看出,公司从某个客户获得的利润越多,越有可能导致客户流失。换个角度来说,客户已经逐步发觉PowerCo提供的定价没有什么竞争优势了。
-
另一个不能忽视的重要特征是一年以来每个用户定价的标准差,即价格的波动。我们可以通过interaction plot进一步看一下价格波动和用电量的关系。
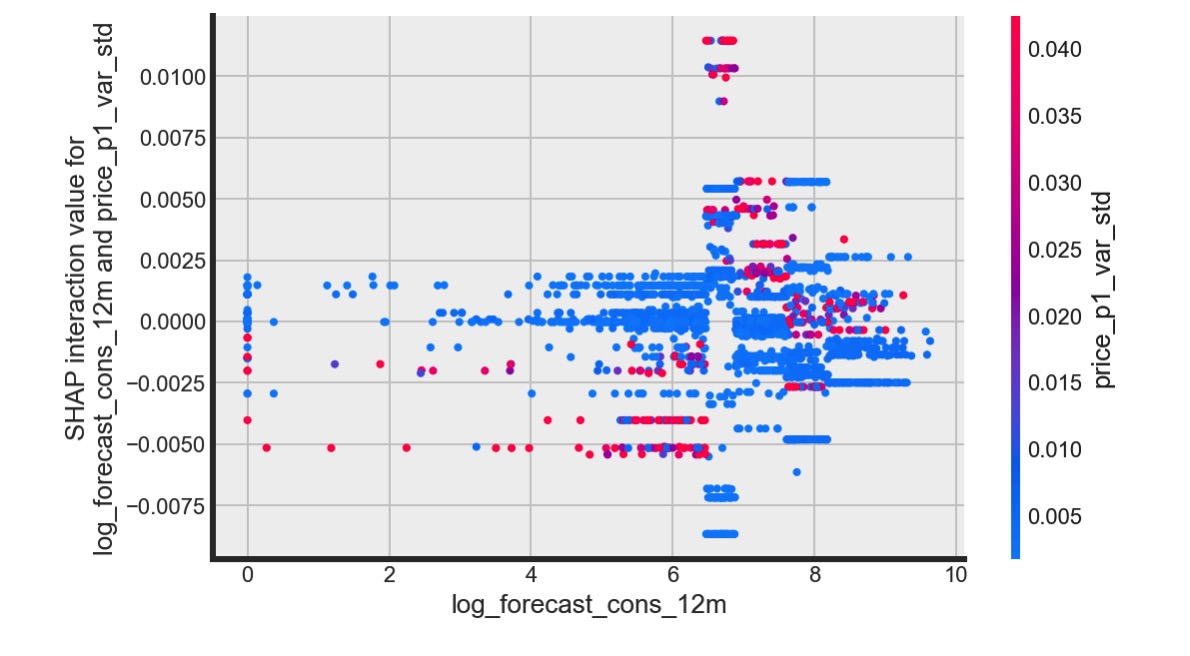
价格波动对用电量两极分化的客户具有特殊的意义。对于用电量大的用户来说,比较大的价格波动会导致他们的流失。可以说,他们是对价格极度敏感的一群客户。但是对于用电量比较小的中小商业客户或普通住户来说,即便价格波动比较小,客户流失概率依然很高。从他们的角度来说,可能是没有获得应有的优惠。
-
从用电量角度来看,约束用电量小的中小型客户,越难留住。
-
从合约更替角度来看,不久之前刚刚启动、更改、更新合约的用户不易流失。这一点与我们的常识一致,客户愿意延续一项服务,要么是对当前服务相对满意,要么是被给与了新的有利条件。需要特别注意是合约已经存续了一段时间的客户,要挽留住他们往往需要额外的刺激。
-
用户初次加入服务时所参与的推广活动对客户流失率也有很大的影响。那些从’ka’推广活动而来的用户后续能够比较好地留存,然后从’lx’推广活动而来的用户有很大的流失概率。我们有必要开展进一步研究,看看那一项推广活动究竟发生了什么。
-
从销售渠道来看,通过’lm’进入的客户在留存率有比较好的表现。
LightGBM模型的另一个便利之处,在于它可以方便地查看其中某几棵树模型究竟是如何分裂的,这有助于我们寻找重要特征的分界点。从以下两个随机选取的树模型可以看出:
- 对于net margin这个特种来说31.190是个重要的分界点。
- 对于经过log化的未来12个月能源用量,9.454是个重要特征。
- 对于价格波动来说,是否小于0.002是个重要分界点。
- 另外,正如我们以上提到的,销售渠道’lm’, 营销活动’ka’,也是划分用户的重要指标。

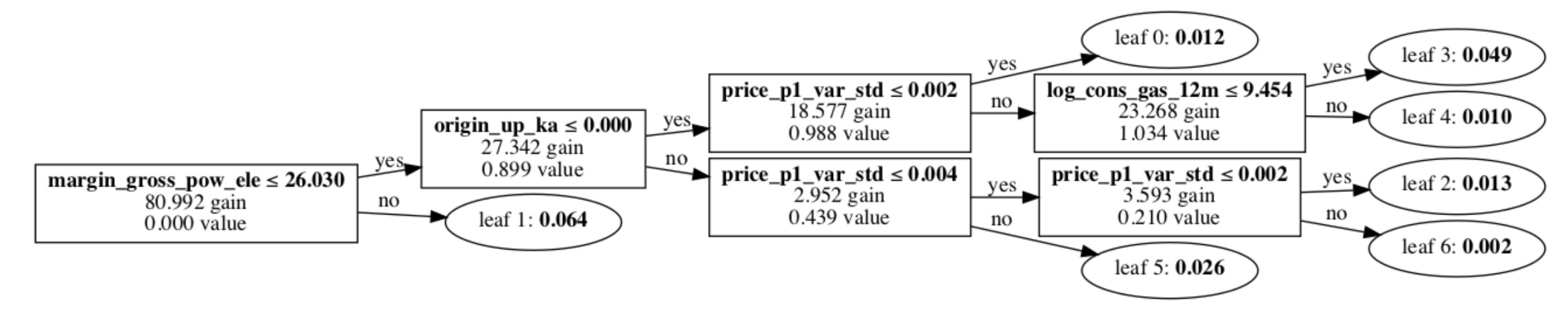
通过以上的模型特征分析,我们基本确认之前的假设是成立的。客户流失,尤其中小客户的流失跟价格敏感有关系。因此,通过打折方案缓解客户流失的逻辑是基本合理。这就引出我们下一步对于打折策略的讨论。
VI.折扣策略的商业分析
在得到客户流失问题的分析之后,客户更加关心的如何缓解现状。当前,客户预期的策略是:向流失概率比较高的客户提供20%的折扣。我们需要针对这个问题提出最优解。为简化这个问题,我们引入一些假设:
- 考虑终止服务的客户会在头三个月之内做出选择
- 当提供一个折扣的时候,现实中只有一部分客户会真正使用这个折扣。我们假设这个接受率大致等同于折扣的比例。
- 使用策略不能以损失总体收益为前提
在这些预设前提之下,我们的任务转化为:寻找一个优化的分界点,向流失概率高于此分界点的客户提供20%折扣,同时希望收益能够最大化。对于这个问题的探索,将主要在测试集得到的预测概率基础上之上进行模拟和估计。
首先,在进行收益估计的时候,我们可以计算得出不存在任何客户流失情况下的基本收益。 
然后,假设所有流失概率高的客户都会在头三个月内退出服务,可以计算得到考虑客户情况之后的收益。

之后,我们可以相应的方法,计算在整个[0,1]范围内选取不同cut-off情况下,给与20%的折扣会来带来多少收益的变化。
最终,我们可以用可视化的方式,呈现这个优化的cut-off和最大收益变化。
针对当前的测试集,我们得到的结论是:
- 当考虑客户流失情况之后,测试集中客户未来12个月的收益为$417726.926。
- 给与20%折扣的最佳cut-off为0.31,此时收益可以增加$12427.844。
如果更进一步思考这个问题,或许20%不是最佳的折扣。那么如何找到一个最佳的折扣与分界值的组合?
其实,仍然依照上述的思路,我们从[0,1]范围中对discount取值,同时从[0,1]范围中对cut-off取值。针对每一组discount和cut-off的取值,计算当前的收益变化。最终,我们针对discount, cut-off, revenue delta三组数据可以绘制一幅3D surface plot。以下曲面图告诉我们,当我们对流失概率在0.54以上的客户给予29% off的折扣时,更够使得收益最大化。此时,收益将增加$42650.95。
VII.Lesson I learned
- 这个项目让我稍稍领略了一下,世界一流咨询公司是如何用数据科学应对现实商业问题的。他们的思路,流程和深度。
- 机器学习和模型的使用并不总是以预测为目的,也可以作为特征挖掘的手段。
- 如果从提升模型预测表现能力的角度,可以根据树模型得到的一些重要分界点进一步对特征进行离散化。鉴于本项目的目标不在于预测,而在于挖掘出重要特征,故而没有做进一步的尝试。
- 折扣策略的商业分析也有进一步优化的空间:
- 当前的假设是每当给予一定折扣,有一部分的客户会接收,我们推断这部分比例相当于折扣本身。更严谨的做法是从retrospective analysis中获得相应的折扣接收比例。
- 另外,也可以抛开这一假设。我们可以将打折后的价格放入模型中,重新预测流失概率。让新计算出的流失概率参与到后续的收益估计中。
- 鉴于用户呈现比较明显的分化特征,可以根据重要划分特征或组合特征对客户先进行customer segmentation,在此基础上再讨论更精细的折扣策略。
- 好的数据科学要以解决商业问题为导向,建好模型做好预测往往只是第一步。如何解释好模型,从中得到强有力的洞见,提出能有助于商业决策的action plan才是数据科学更有价值的环节。