机器学习总览
100-Same Tree | Links:
什么是机器学习
- 机器学习是人工智能的一个重要分支
- 机器学习的核心是数据驱动,即通过算法总结数据的规律模式,以实现预测(监督学习)和描述(无监督学习)的目的
- 机器学习的重要能力在于泛化:机器学习模型对于未知数据的预测能力
监督学习与无监督学习
监督学习
- 训练集给定数据,给定标记
- 目标是用于预测
- 分类问题:根据数据样本抽取的特征,判断其属于有限类别中的哪一类,输出结果是离散值
- 分类问题的目标在于确定决策边界
- 评判标准:Accuracy,ROC-AUC curve
- 回归问题:根据数据样本抽取的特征,预测连续值结果
- 回归问题的目标在于拟合样本分布
- 评判标准:RMSE,MAE,R2
无监督学习
- 给定数据,无标记【没有Label,没有答案】
- 目标是寻找数据隐藏的模式
- 聚类分析 clustering
- 对数据分组或挖掘数据的关联模式
- 常用于EDA阶段发现隐藏的模式或者对数据进行分类
- 降维 Dimensionality Redeuction
- 保持数据的主要特征,去掉不必要的特征
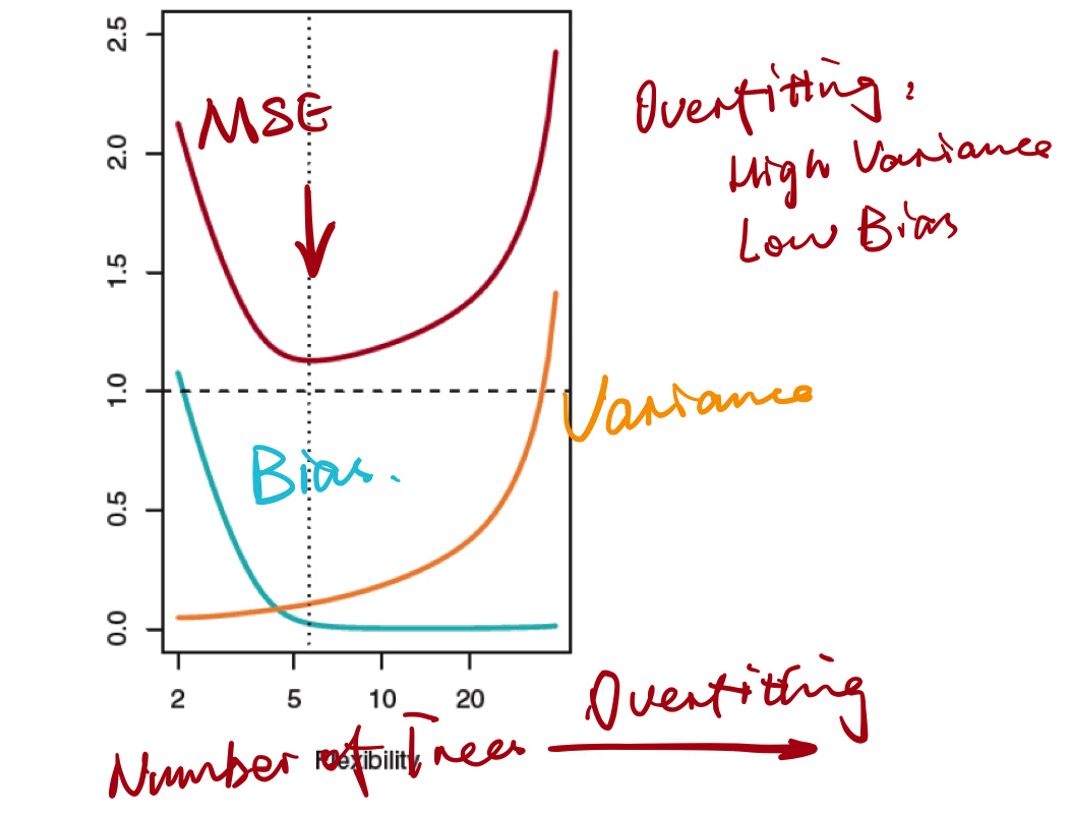
损失函数
- Error = Bias + Variance + Noise
- noise是不可消除的部分, bias + variance是可消除的部分
- 损失函数描述的实际是bias + variance, 进而争取优化
方差与偏差
- 偏差bias:模型预估平均值与真实值的差异
- 方差variance: 模型预估与其平均值的差异
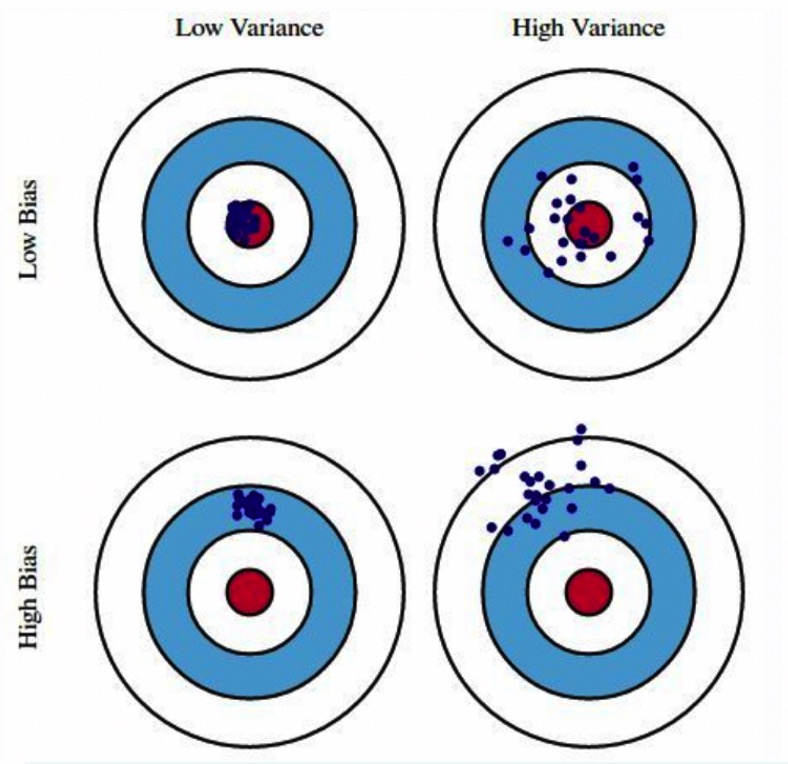
bias vs. variance trade-off
- 理想状态追求的是:low bias, low variance, low MSE
- 现实中是bias和variance之间的权衡
- 更应该关注的是目标函数的极值:例如最小化MSE
偏差bias的两种衡量方式
- 直接衡量bias,例如MSE
- 代理bias,例如交叉熵。
- 交叉熵是通过信息论的方式衡量模型给出的概率分布和真实概率分布的差异。交叉熵不是直接衡量bias(几个分对了,几个分错了),但是方向是一致的,随着错误的增加单调递增。
改善方差的本质
- 控制搜索空间,使得机器学习模型学到更多的是信息而不是噪声
- 改善方差的方法:正则化
目标函数
- Objective funtion = loss function + regularization
- 机器学习结构是training loss和regularization的结合
- 希望模型能用于预测,尽量缩小预测值和实际值之间的差异
- 希望模型简单可控
- 机器学习的最终目标:能取得可靠结果的最简单模型
正则化的本质
- 核心思想:限制参数搜索空间【只能在相对固定的一个空间内搜索参数】,不能无法无天
- 线性模型:L1/L2正则化,限制参数大小和数量
- 树模型:限制树的深度,树的数量,分裂条件