KNN
100-Same Tree | Links:
Overview
- 非参数算法
- 优:没有关于数据特征的数学表达,更灵活
- 劣:难以解释
- Lazy Learner: 在测试集预测的时候才开始训练,预测时计算量大,对大数据不友好
KNN核心
- 使用距离来衡量相似性 ->距离越近越相似
- 用近距离的neighbor的分类来预测当前点的类别
- 对于给定K,和当前observation x: KNN从训练集中寻找最接近x的K个样本,由他们投票决定x的分类
操作事项
- 特征需要实现standardize / scale
- 尝试不同的距离/相似性算法:默认使用欧式距离
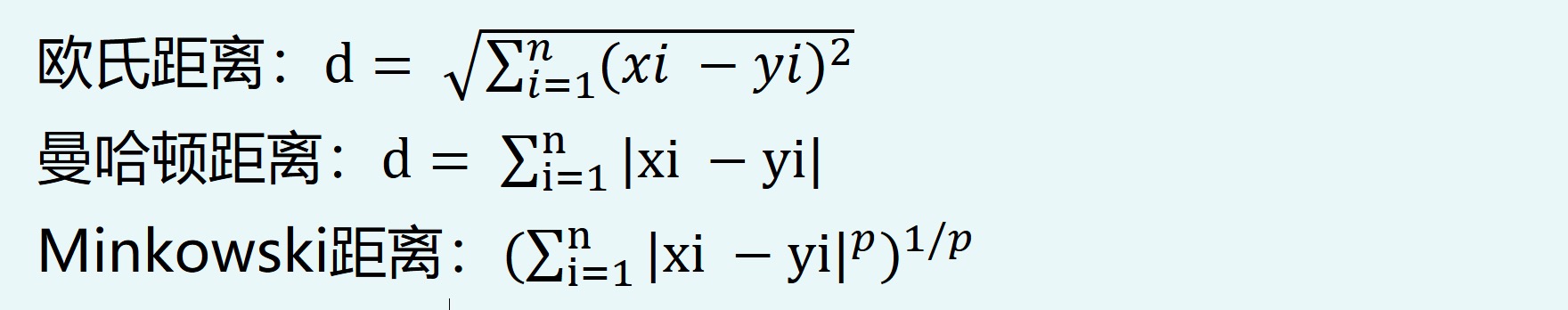
- K取奇数以避免投票平局
- 投票时可以给closer neighbor赋予更多的权重
- 通过cross-validation找合适的K值: Varaince / bias trade-off
- 对于不同K值,比较KNN-score(accuracy)
- Large K: low variance, high bias
- Small K: high variance, low bias
- 对于不同K值,比较KNN-score(accuracy)